

Databricks SQL Scripting
SQL Server infiltrates the Lake House


I would be lying if I said a little bit of me didn’t die when I first read this, that is, SQL Scripting released by our friends at Databricks.
Don’t get me wrong, I hold no deep-seated grudge towards Databricks for doing the obvious. You must give the masses that which they desire lest they turn and tear you.

We Data Folk are simply gluttons for punishment, our own worst enemies, yet we get the job done most of the time, eh? Why did I die inside just a little bit?
Because I’m from the old days, like the old, old days when SQL Servers roamed the earth, spewing TSQL and Stored Procedures across the land with SSIS riding on its’ back.
Some of you will know the dark, evil days of which I speak; others of you were born in light and simply are unaware of the ages past in which Business Intelligence Engineers and Data Developers fought hand-to-hand combat with SSMS, deadlocks and other such terrible beasts.
Can you tell I might have a little PTSD?
What exactly is SQL Scripting in a Databricks/Spark context.
Ok, so enough with the old man stories, I can’t help it, what exactly is SQL Scripting in this context, and who cares?
“You can employ powerful procedural logic using SQL/PSM standard-based scripting syntax. Any SQL script consists of and starts with a compound statement block (BEGIN ... END). A compound statement starts with a section to declare local variables, user-defined conditions, and condition handlers, which are used to catch exceptions.”
- Databricks
This abomination … ehhh … I mean super helpful procedural SQL can be encapsulated as … you guess it, a stored procedure. It’s funny how history always repeats itself.
“Using the CREATE PROCEDURE statement you can persist a SQL Script in Unity Catalog. You can then GRANT the access to the procedure to other principals. Those principals can then use the CALL statement to invoke the procedure.”
- SQL Stored Procedure
Let me drop a simple example here so you can see both SQL Scripting and SQL Procedure in code so it hammers the point home of what we are dealing with.
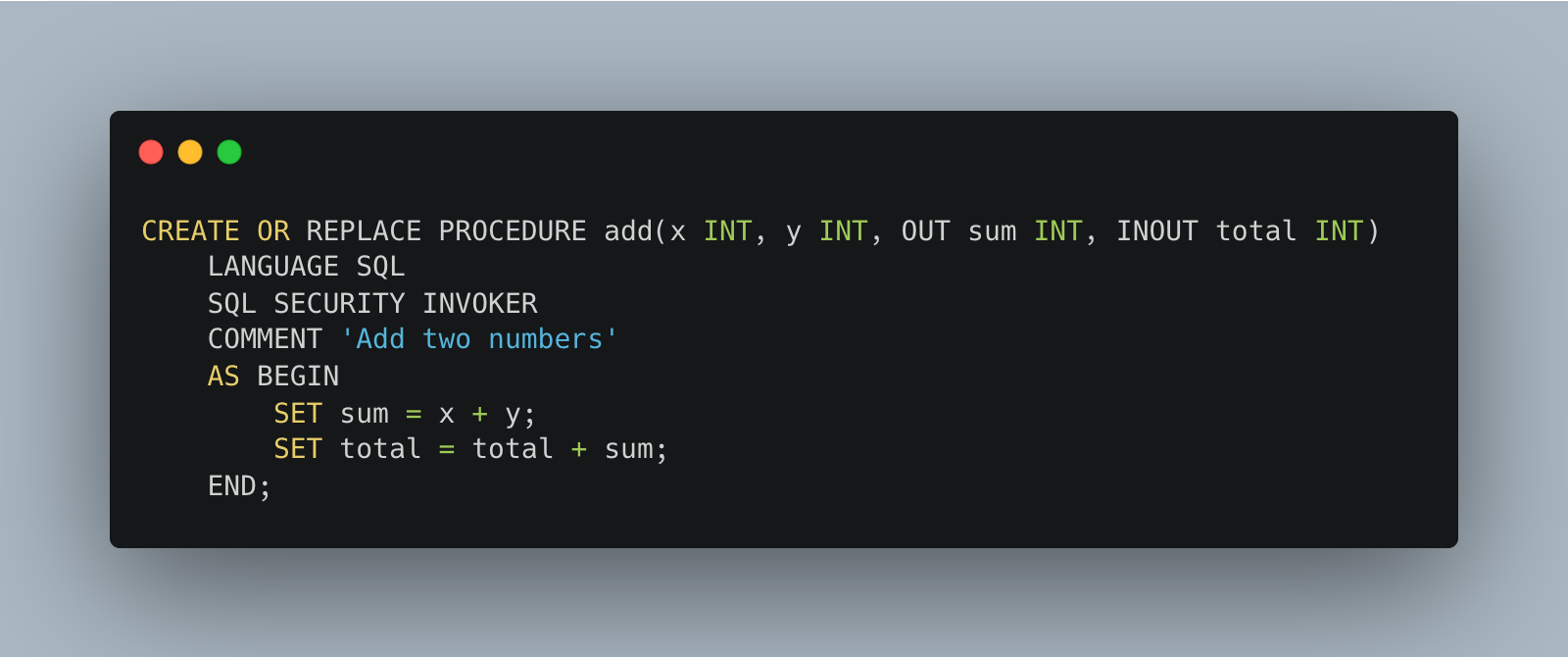
Both these examples are from the official Databricks docs; they aren’t rocket science and mostly just show you what is possible.
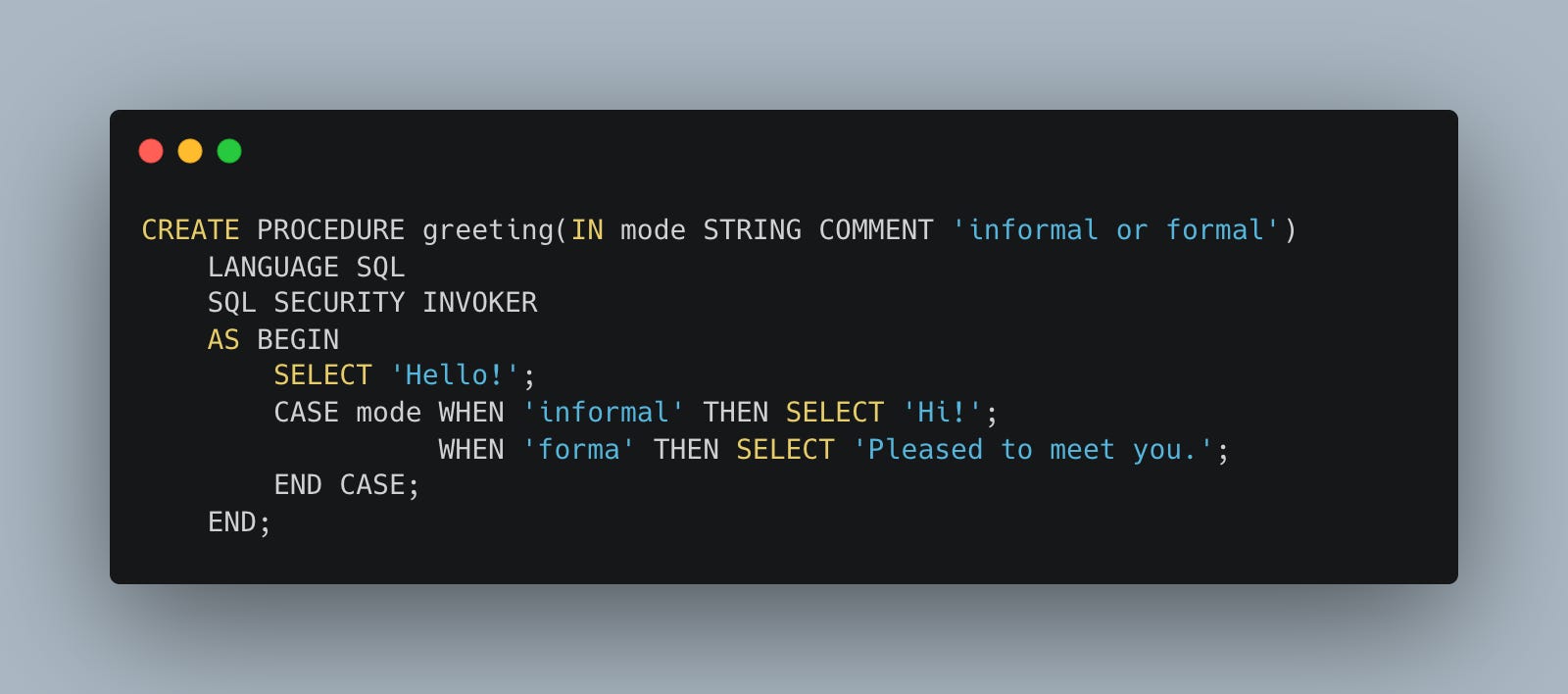
I mean, as you can see from these examples, you can pass in whatever params you like and can return whatever … and the sky is the limit to what goes between the BEGIN and END statements.
So what’s the problem grumpy pants?
This is sort of a loaded question, at least for someone from my generation anyways. To be honest, we have lived through this sort of architecture that drove all sorts of pipelines for decades … there was a reason it was abandoned.
There is a thin-red line between HOW and WHERE we should solve certain business problems.
Let me put it like this … we have two general options as programmers to solve problems that present themselves. Each has it place, and they both can work in unison, walk hand and hand, wherein the best results lie. If you start to force square pegs in round holds, things will go bad … eventually.
Your two options are …
SQL
SQL is best for working on tabular (sets) of data, crunching uniform type transformations across wide swathes of data. It just works well for this sort of thing.
Classic programming language (Python, Java, Rust, Golang, etc)
Programming languages work well on minute and specific procedural tasks and data manipulations.
Methinks this is where the stored procedure went wrong in classic SQL Server warehouse environments. It was something that was inherently used to be incongruent to SQL. Not all the time, just 50% or more of the time.
Also, stored procedures suffered from another MAJOR implementation flaw. Invisibility and Obscurity.

The question is, can Databrick’s SQL Scripting avoid these mostly human implementation problems?
I suppose one could argue this is no inherent reason that simply encapsulating code inside a thing is bad, it’s HOW it’s done that creates the problem.
What used to happen back in the day is that …
some long and complex SSIS package would run
various tasks would run
a series of stored procedures with TOO much logic would run
the stored procedure itself if mostly invisisble
someone has to go find it
debug it
etc
And that’s if everything worked perfectly. What you think stored procedure hell is something from the past? Guess again.

Stored procedure hell is alive and well.
If this sort of “SQL scripting” is so destructive, than why is it still going on, and why is Databricks bring such features to their users?
Because it’s humans that make bad decisions … not code.
Let’s go back to the definition of what SQL Scripting is …
“Creates a procedure in Unity Catalog that takes or modifies arguments, executes a set of SQL statements, and optionally returns a result set.” - Databricks docs
I mean it sounds like a powerful abstraction … because it is. Powerful things can be used for both good and bad purposes. It’s up to the Engineers to make correct decisions about HOW and WHEN to use a stored procedure.
It’s probably true that SQL Scripting and stored procedures in general suffer from the same fate and pitfalls they have for last few decades.
If you cram too much logic in one place, it sucks.
If you hide and obfuscate data pipelines and code, it sucks.
There is no free lunch, the fancier you decide to be the more you will pay the price later on down the road. This feature will suffer from the same problems your SQL right now suffers from … except that SQL Scripting will exacerbate the problem.
keep all logic clean and simple
put everything in source control
make sure all step(s) of a pipeline are observable and discoverable.
What is my opinion of Databricks SQL Scripting and the introduction of stored procedures into the Databricks landscape? I have none.
I’m sure there are wonderful use cases. There are also a lot of trigger happy engineers who write bad code, and they will indeed, as in other circumstances, abuse this feature.
Well written post, especially calling out the importance of considering the ‘how’ and ‘when’ transformations should be implemented. It hit the nail on the head for me, and made me chuckle (so perhaps I didn’t cry at recalling past pain debugging logic “hidden” in stored procs)!
As someone who is used to warehouses running on SQL Server, with SSIS and stored procedures, I am wondering how does the alternative look like? I guess the Databricks alternative is a Python notebook - how is it better? Business logic is still stored in a code, why would a Python code would provide better visibility than an SQL code? Both a stored procedure and a notebook can be version-controlled, so I do not see a difference here either. There is no GIT integration for stored procedures in Databricks yet, but code can be still pushed into a GIT repository, and GIT integration could be also implemented in the future in Databricks. For testing, I can imagine improvements to what is possible with a SQL stored procedure, but I would not say that a stored procedure is hard to test either. I guess it also depends on the kind of stored procedure in question. Instead of CTEs or nested queries, we often use temporary tables in our codes, which lets us check data for intermediary steps, the same way as a notebook allows you to.
Probably I am just not familiar enough with more modern approaches, so I would appreciate if you could point me in the right direction where I can find the answers. (I have read quite a lot of Databricks documentation, and it did not help.)