

Delta Lake vs Apache Iceberg. The Lake House Squabble.
... the real deal.


I learned something important early on in my career, I can still remember the conversation, which funnily enough, happened not at work, but at a Bed and Breakfast of all places.
Sitting inside a huge and hand-hewn log cabin, nay, mansion, talking to the owner who had just come in from cutting and bailing hay, he was telling me about a book he had just written on “emotional intelligence.”
He had retired early and wealthy from consulting, he summed up what he had done for a living that was so lucrative.
“I spent my career teaching adults how to share and get a long, kinda like a glorified kindergarten teacher.”
No solving world hunger, not building some fancy SaaS tool, nope, he was happily retired living inside a giant bespoke log mansion because there is apparently enough fighting that goes on in high places of power that kept him busy and rich, and probably still so.This story is to illustrate a point, a sort of table setting to prepare us for the discussion to come. What is that saying? Something about man’s inhumanity to man?
That finally brings us, unsurprisingly to today’s topic, which should be a fun one. Let’s grind our axes, polish our armor, and kiss our loved ones goodbye. It's time to head into battle.
Yes. There indeed is a Lake House battle raging.
First, anyone who says there is NOT a Lake House battle brewing and bubbling most likely has an agenda tied to one or other of those dueling sides. It’s so obvious with all the saber-rattling that has happened in 2024 that it’s hardly worth my time, or yours, to even defend the position that there is indeed a Lake House battle raging.
I’m sure Hudi might want to interject itself, but we all know that the two clear contenders are Delta Lake and Apache Iceberg.
Note: Full disclosure, I will be as fair as possible, although I prefer Delta Lake simply because it’s better than Apache Iceberg.
I think for our younger generation, and because I’m old and like to tell the same stories, like your Grandma, that we should do a quick little visual history lesson on Lake Houses, and what led to where we are today.
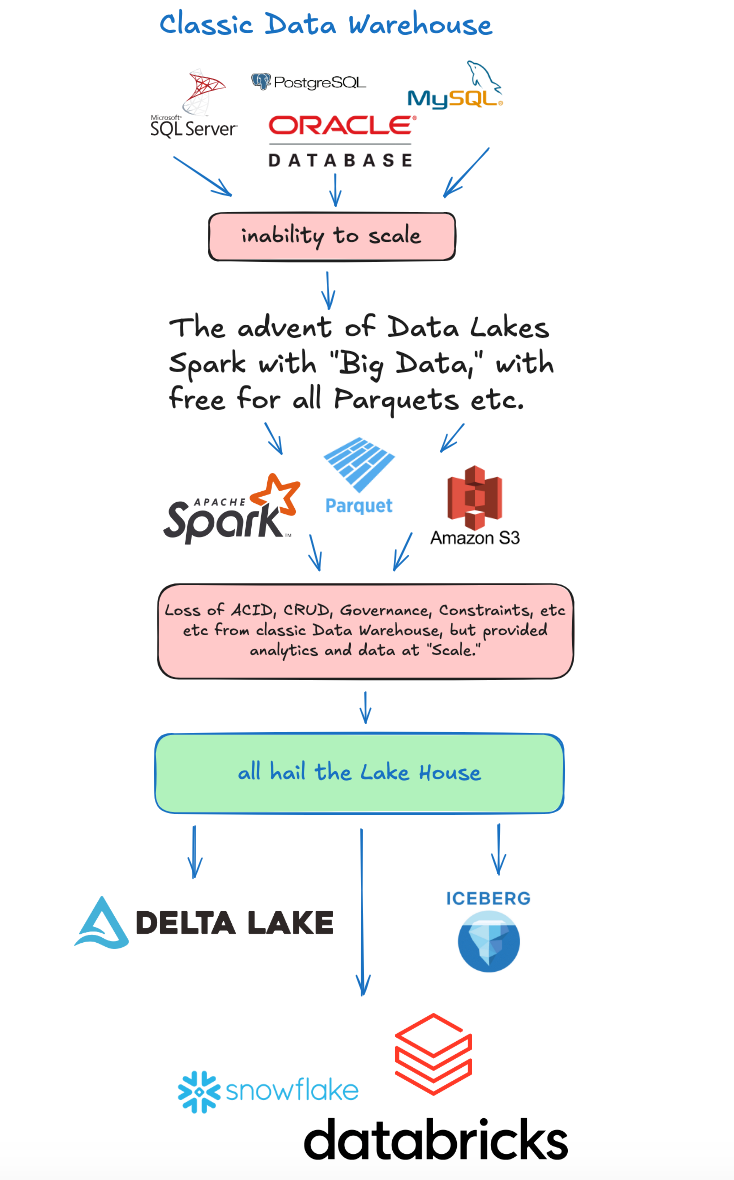
More or less, the Lake House was the natural progression from the classic Data Warehouse of the Kimball years with SQL Server, Oracle, etc etc. Those systems struggled to scale with the increasing size and velocity of incoming data.
This led to the increasing adoption of …
Tools like Apache Spark, etc.
Storage like Parquet files in cloud storage (s3 etc).
While this solved the scalability issues, this sort of Data Platform had ALOT of shortcomings that were solved with the classic Data Warehouse.
Schemas
Constraints
Governance
ACID
CRUD
etc.
Enter the Lake House.
“In the context of data, a Lake House refers to a modern data architecture that combines the best features of a data lake and a data warehouse to create a unified platform for managing both structured and unstructured data. It is designed to provide the scalability and flexibility of a data lake, with the performance and management features of a data warehouse.”
Back to the Lake House battle.
Ok, I told you I was going to tell you a story, didn’t I? I think it’s important to understand the past to help us hone into why exactly there even is a Lake House battle.
There is another saying about “follow the money,” or something along those lines right?
This is the “why” of the Lake House battle.
Cloud Computing Market:
In 2023, the global cloud computing market was valued at approximately USD 602.31 billion. It is expected to grow at a compound annual growth rate (CAGR) of 21.2%, reaching around USD 1,266.4 billion by 2028.
Another estimate places the market at USD 626.4 billion in 2023, with projections to reach USD 1,266.4 billion by 2028, growing at a CAGR of 15.1%.
-----
Data Analytics Market:
The global data analytics market was valued at USD 41.05 billion in 2022 and is projected to grow from USD 51.55 billion in 2023 to USD 279.31 billion by 2030, exhibiting a CAGR of 27.3% during the forecast period.
Another report indicates that the data analytics market size was USD 49.03 billion in 2022, with an expected CAGR of 26.7% from 2023 to 2030.In other words, there is a lot of money at stake. People have built tools and invested many millions and billions into developing their products to integrate into these tools. Of course, they are going to care what you decide to use.
We are talking about the storage layer … but …

When we talk about Delta Lake vs Apache Iceberg, yes we are talking about the storage layer of the Lake House, but it’s not that simple, it never really is.
These systems built by Databricks and Snowflake, for example, sell themselves as Data & AI Platforms, your late-night TV, bundle it all into one, get it while it lasts tool set.
You don’t typically, for example, migrate to Databricks in a vacuum, when move to Databricks, you are deciding that you are a Spark + Delta Lake shop, that is going to be the foundation of your entire system.
Sure, I know you CAN do other things, but the CAN and the .01% of people shouldn’t really shape our conversation on this topic.
I mean ask yourself, why did Databricks by Tabular for a billion flipping dollars?
Why is UniForm now a thing for Databricks/Delta Lake?

Why do you think AWS chose Apache Iceberg for its S3 Tables? Because it’s a battle, my friend.
What if the data market solidifies on a single tool, Iceberg, or Delta Lake? Well, that leaves the people who’ve invested a majority amount of their time and energy into the “losing” side are now going to have a lot of work and explaining to do.
Note: At this point, my personal opinion is that both Delta Lake and Iceberg are going to be with us for the long term. Both tools are so deeply entrenched into so many ecosystems and downstream SaaS that at this point, neither can simply disappear.
Realistic comparison of Apache Iceberg and Delta Lake.
Like always, I will do a super high-level technical overview of both tools and thereby send many different acolytes into screaming and foaming rage of madness. It’s why I do what I do.
I always like to start with GitHub profiles of both tools, I know it can be a flawed thing, but it’s not like that’s our sole deciding point, we are just going to use it give us an idea of what *might* be going on in the community.
- delta

- iceberg


Take from that what you will, you’re smart people. What else should we know about these two projects.?
Iceberg was created in 2017, 2018 it went to the Apache Foundation.
Delta Lake was created in 2017, and open-sourced in 2019.
What is Apache Iceberg?
Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data while making it possible for engines like Spark, Trino, Flink, Presto, Hive, and Impala to safely work with the same tables, at the same time.What is Delta Lake?
Delta Lake is an open-source storage framework that enables building a format-agnostic Lakehouse architecture with compute engines including Spark, PrestoDB, Flink, Trino, Hive, Snowflake, Google BigQuery, Athena, Redshift, Databricks, Azure Fabric and APIs for Scala, Java, Rust, and Python. With Delta Universal Format aka UniForm, you can now read Delta tables with Iceberg and Hudi clients.This really isn’t a post about the technical underpinnings of HOW both Delta Lake and Apache Iceberg work, despite whatever the pundits may tell you, these two tools generaly work the same way.
parquet files store the data in the background
some sort of “manifest” or “transaction log” file to hold metadata.
Of course, the differences keep going deeper and books have been written about them, but that’s not why we are here today.
Delta Lake and Apache Iceberg from a Python perspective.
Like with any good data tool, we should inspect that tool from a Python perspective.


Let’s be real, 90%+ of Iceberg and Delta Lake interactions happen with PySpark, so we need to check out that as well. So we should test that out as well.
We should also look at the download stats for both pyiceberg and deltalake. This can give us some sort of indication of adoption in the wild.


If we look at downloads last week AND last month, the deltalake Python bindings blow pyiceberg out of the water. (the last day numbers for Iceberg are probably skewed because this was when S3 Tables were released)
Again, take from that what you will, you are smart folk, I think, there are some things you can read between the lines in those numbers, like it or not.
A side note about Catalogs.
The whole Catalog dealo is another rabbit hole that we must TRY not to go down during this discussion, yet at the same time, it is also a cornerstone of most Data Platforms, and the integration between a Catalog and say a Delta or Iceberg tabe is incredibly important.
Unity Catalog
Iceberg Catalog
REST
Hive
JDBC store
As a whole, Unity Catalog has come a lot farther and is more straight forward to work with than the fragmented Apache Iceberg Catalog landscape.
Maybe we will come back to Catalogs later on, not sure.
General Python support for Iceberg and Delta Lake.
Another aspect of these two dualing storage systems is their general adoption of NON-Spark Python packages. Again, I find this sort of stuff tells a story. It cuts past all the marketing fluff from either side of the aisle and proves almost to the point of putting the other to bed, that “one tool overcomes the other.”
For example, if one side claims to be the winner of the Lake House storage format wars, yet lacks adoption in the general end-user Python packages being used by the masses on a daily basis, I can assure you that you have found a liar, liar, pants on fire.
We could also extend it past just Python packages, to just programming tools in general.
As you can see below, unfortunately for Iceberg there is a serious lack of FULL support for read and write from many major tools that already include Delta Lake full support.
Note: An astute reader told me DuckDB doesn’t fully support Delta. It’s always good to be like those Bereans and search out the truth for yourself. I’m only human.

I will let that sink into your giant brains and come up with a reasonable explanation for the above. Also, there is another BIG REASON that Iceberg falls behind on these tools along with local development. It explains the above. We will cover that below.
And so, the show goes on.
Technically, is there any difference between Iceberg and Delta Lake?
Although this seems like an important question on the surface, one could surmise based on all the data we have looked at so far, that these two behemoths of Lake House storage formats are pretty much neck and neck, although one seems to be behind the other in terms of overall adoption.
If one tool clearly was far superior to the other in features and performance offered, then the race would not be so tight in the first place.
Of course with different implementations of the same feature, they are indeed different tools, but in the end your usage of either Delta Lake or Iceberg via say, Apache Spark, is going to get you to the exact same spot.
As I mentioned above there probably IS a reason that Iceberg lacks adoption across a wide range of tools like Delta Lake. I have a feeling we can sus out the reason why by simply doing a experiment.
Let’s create a 10 million row Iceberg and Delta Lake table and simply FEEL what the developer experience is like, and how much work it takes.
Up first, Apache Iceberg.
The easiest way to do all this, and for you to follow along, would be to use Docker, we will use a basic Python image to do the work.
#bash
docker run -it python:latest /bin/bash Once inside we can pip install the below tools we might want to play with.
#bash
pip install pyiceberg polars duckdb getdaft[deltalake] pyarrow deltalakeWe are also going to use the open-source tool datahobbit to generate a test dataset we can use to create Iceberg tables. To do that, we need rust.
#bash
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
export PATH="$PATH:$HOME/.cargo/bin"
git clone https://github.com/danielbeach/datahobbit.gitLet’s generate the initial dataset we can read with a tool and write to an Iceberg table.
#bash
cd datahobbit
cargo run -- schema.json output.parquet --records 10000000 --format parquetWe can see our parquet files now …
#bash
root@6197c5643da2:/datahobbit# ls
Cargo.lock output.parquet_0.parquet output.parquet_2.parquet output.parquet_5.parquet output.parquet_8.parquet python target
Cargo.toml output.parquet_1.parquet output.parquet_3.parquet output.parquet_6.parquet output.parquet_9.parquet schema.json
README.md output.parquet_10.parquet output.parquet_4.parquet output.parquet_7.parquet pyproject.toml srcLet’s use pyarrow to read these parquet files and write an Iceberg table. If you are curious, this is what the data looks like.

Note: this will NOT be as easy as Delta Lake, we HAVE to have a Catalog configured to Iceberg to work, and we will have to include pyiceberg+ in to get the job done.
Let’s continue with our Catalog work that is REQUIRED to play with Iceberg locally, including another pip install that is required …
#bash
mkdir /tmp/warehouse
pip install sqlalchemyOnce this is done in Bash, we can switch over to Python.
# python
import pyarrow.parquet as pq
from pyiceberg.catalog.sql import SqlCatalog
from glob import glob
warehouse_path = "/tmp/warehouse"
catalog = SqlCatalog(
"default",
**{
"uri": f"sqlite:///{warehouse_path}/pyiceberg_catalog.db",
"warehouse": f"file://{warehouse_path}",
},
)
catalog.create_namespace("default")
files = glob('/datahobbit/*.parquet')
df = pq.read_table(files)
table = catalog.create_table(
"default.test",
schema=df.schema,
)
table.append(df)You might be asking me a question, a question that I asked myself. Why can’t I simply use something like Daft to read and write? Well, for example, to write an Iceberg table in Daft you need an actual pyiceberg table to pass to Daft, if you go to pyiceberg you NEED to have Catalog configured to write a table as far as I can tell.
It’s a daisy chain of crap. I mean I went through all the learning steps just to prove the point, but others will just stop half way when they figure out they need to configure a catalog and get lost in the detritus of the internet figuring out how to do that.
The simple truth is we humans are lazy, Data Engineers are no different. For a tool to gain widespread adoption among users AND gain support for tooling integrations … it must be “Easy” to use.
Take for example the following Delta Lake setup if I so desire, and want the ability to locally develop with Delta Lake, LIKE ANY GOOD ENGINEER would want while building our larger data platforms.
The same thing for Delta Lake.
Here it goes, hold on.
import daft as dft
df = dft.read_parquet('datahobbit/*.parquet*')
df.write_deltalake('test')Before you say I’m cheating and not being fair to Iceberg, I would have you note the above in Daft for Delta Lake is just as easy in DuckDB, Polars, etc.
Remember, I can’t turn to Polars, DuckDB, etc to write Iceberg tables … they don’t have support.
Details matter because Engineers have to worry about them. If you’re trying to decide between Delta Lake and Iceberg for your Lake House, including local development systems, etc, what are you going to choose?
I would have to have a REALLY good reason to choose Iceberg over Delta Lake at the moment.
Simply based on tooling integrations and ease of development.
Let’s be honest.
I think we should stop and just be honest with each other, the whole reason the Battle For the Lake House Storage Format even exists is because we have our own pet favorites for various and sundry reasons.
If you’ve been using Databricks for years, you would look at what Iceberg users have to go through to even piddle around with it locally and ask yourself why in the hell they would put themselves through such nonsense when something better exists.
On the other hand, if you’ve used open-source Apache Iceberg, or one of its many closed-source variants, it’s just what you are used to, and your human, you aren’t going to switch.
Plus, seeing something like the AWS S3 Tables announcement is going to make you stand up and pat yourself on the back, “I was on the right side.”
Clearly that is just a biased take, any moderate person who simply goes down the list of exploring the two projects side by side, and comparing them for what they are, including with code, is going to come to the obvious conclusion you can see above.
Delta Lake is better. Iceberg is mid at best.
Ha Ha! Don’t forget, I’m just another biased user who loves Delta Lake because its better than Iceberg. But, you can use whatever you want, don’t let anyone tell you otherwise.
At the end of the day a Lake House platform built with Iceberg is going to give you the same analytics as one built with Delta Lake. If we get to our goal, the middle doesn’t matter that much.
For completeness, here is a simple cli tool that let's you read and write Iceberg tables with Datafusion even without a catalog:
https://github.com/JanKaul/frostbow
Disclaimer: I'm the author of the tool.
The part that crystallizes this post the best and shows just how much further along delta is than iceberg for developers is the 2-liner you had on daft reading a parquet file and then writing it to the delta format:
- no catalog nonsense
- no extra package to convert from one df format to arrow
- no needing to lasso a table object
- like you said, working with iceberg (when not on pyspark) is a “daisy chain of crap” which is 100% facts