

DuckDB processing remote (s3) JSON files.
... just because we can


In a quest not to get too bored in the Data Engineering world, with Databricks and Snowflake being old hat these days — it’s always good to go looking for interesting things to do. Interesting things yet obvious things, the simple things, things other people forget about with all the stars in their eyes.
I’ve been enjoying poking at DuckDB these days when I get the chance; it’s a simple tool that exemplifies the best of Engineering …
simple
fast
lightweight
Today, I was reading something on Reddit about crunching JSON files with PySpark. I’ve been there. It was actually one of the first big Data Engineering projects I worked on. Processing millions of new JSON files showing up daily in an S3 bucket with AWS Glue and Athena. Ahhh … the good ole’ days.
It made me wonder how DuckDB would handle this problem — JSON files in S3. DuckDB is an SQL tool known for being extremely versatile in its use cases. Can we add JSON to the list?
DuckDB with JSON files (in s3)
So, first things first, we need some sort of reasonably sized JSON dataset to work with for our little experiment, when in doubt, I always head over to GitHub and peruse through the open-source dataset section. I decided to poke at Toronto open data.

What could be more exciting Toronto Island Ferry Ticket Counts … woohoo.

Once we get that data into S3, now we can get the meat and taters of what we want to do.
Reading JSON with DuckDB
So, I wasn’t sure what was going to happen when the two words DuckDB and JSON came into my mind, I figured as a SQL tool it might not have first class support for JSON files, but oh boy was I wrong.
Note: DuckDB is the GOAT for integrations of all shapes and sizes.
“The DuckDB JSON reader can automatically infer which configuration flags to use by analyzing the JSON file.” What a wonderful tool, a simple READ_JSON() is all we need??!!
Let’s giver er’ the old one-two punch-a-roo. All code is available on GitHub.

And what happened?

Of course it worked you hobbit … “oh ye of little faith.” I’ve learned that DuckDB rarely disappoints with it’s integrations and features (unless that something is OOM).
Now before you just scroll on past and move on with life because the above code was so simple and tiny and the result so ho-hum, I beg you to stop a minute.
I remember the days when we had to unwind JSON files with code both ways uphill in the rain and snow, throw salt over our left shoulder and spit some blood on a dead crow at midnight to be able to run SQL straight on top of a JSON file(s).
I don’t know, it just seems incredibly helpful to be able to RUN SQL ON JSON files. In the past I would have written code to convert the CSV files to something else … CSV, Parquet, etc … and then after writing that code/pipeline … finally run some SQL on it with Spark or something else.

I mean isn’t there something just beautiful about that?
Not every tool can do something so easily. Take Polars for example. It can’t seem to understand the S3 file path out of the box.
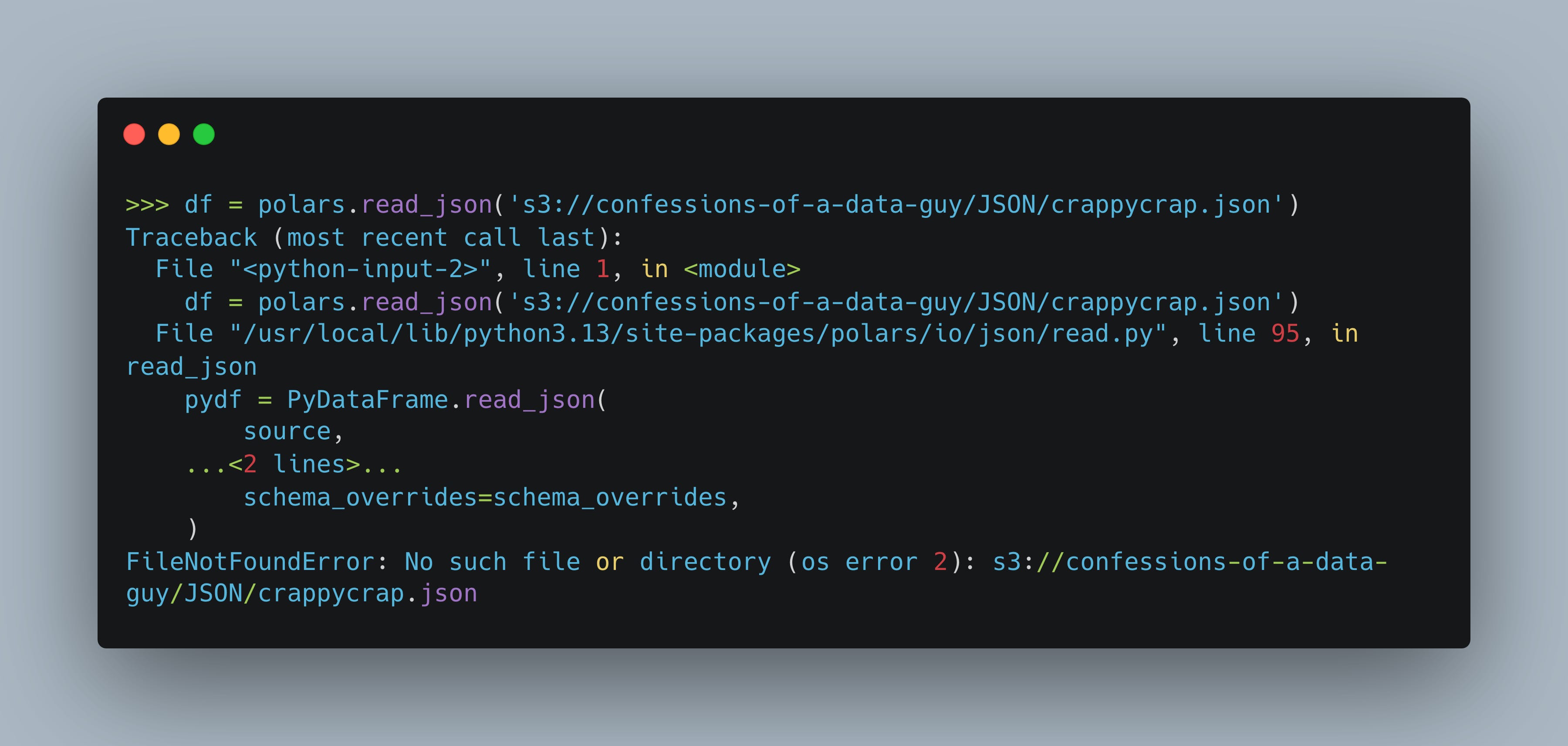
I mean it’s good to know that apparently DuckDB is the class of it’s own when it comes to processing remote JSON files in cloud storage, which by the way, is a super common usecase.
Do you think it can handle multiple JSON files automatically? This is sort of important for a Production use case, there will be a lot of times when you have a whole bucket of JSON files needing to be processed.
I went ahead cloned that JSON file we were using into the same bucket again, let’s try to read both files at once.

All I did was add the “*” wild card to the URI and it appeared to work, you can see our numbers for the same query doubled, just like we would expect. Wow, powerful!
All code is available on GitHub.
Thoughts
Next time you have to deal with a bunch of JSON files, instead of writing a pipeline to transform that data and massage and unpack all that data into another format, why not reach for DuckDB?
It can cleanly read multiple JSON files in remote storage and is able to run SQL directly on those files with only a few lines of code.
It’s hard not to love DuckDB for this sort of incredible use case, even for someone who’s gotten tired of SQL after a few decades of writing it.
In my opinion, its stuff like this, the little things, that will make DuckDB a tool that is here to stay and a powerhouse of data processing for years to come.
What cool stuff have you done with DuckDB, have you used it all yet??
Reading any system logs on object storage (often in JSON) is actually a common use case for DuckDB!