

DuckDB + PyIceberg + Lambda
... with Cloudflare's R2 ...


Every once in a great while, I feel it’s good to pay some penance, to do a thing that isn’t fun at all, that you find appalling and horrible. I tell my children regularly that it’s a good thing to struggle; to do a “hard thing,” makes ya’ stronger.
We need all the strength we can muster with AI bearing down on us. We all might soon be on the streets fighting each other for scraps of bread.
What are those hard things for me? I’m sure some of you could guess the answer outright.
Now, don’t get me wrong, there is nothing wrong with Apache Iceberg and DuckDB. Clearly, they are strong contenders in the Data World. I’ve just had my issues with them in the past. I’ve got a bit of a hard edge, maybe a streak of hard-to-forget and bitter at times if you give me problems.
__________________________________________________________________
Please take a moment to check out this article’s sponsor, OpenXData conference 2025, without them this content would be possible. Please click the links below to support this Newsletter.

The data infrastructure event of the season is here → OpenXData conference 2025
A free virtual event on open data architectures - Iceberg, Hudi, lakehouses, query engines, and more. Talks from Netflix, dbt Labs, Databricks, Microsoft, Google, Meta, Peloton, and other open data geeks.
May 21st. 9am - 3pm PDT. No fluff. Just solid content, good vibes, and a live giveaway if you tune in!
__________________________________________________________________
Anyway, let’s pay some penance by building an AWS Lambda that uses DuckDB and PyIceberg to ingest and transform data, landing the results in an Iceberg table.
Really, this is about testing what everyone else talks about, but never does. People from all walks of life pontificate on the likes of DuckDB and Apache Iceberg, singing praises where they may, or may not, be due.
As per usual, I will leave the talking heads to talk about what they don’t know or have ever tried. For you and me, we shall plumb the actual depths of what can be done, how these tools act in the real world, under real pressures.
Setting up the background and data.
First, since I like pain, but not that much, let’s get an Iceberg compliant table setup, and I’m going to use Cloudflare’s R2 Data Catalog and Iceberg option. Read more about that below.

So what we actually want to do with AWS Lambda + DuckDB + PyIceberg is see if we can actually ingest raw data, mung it with DuckDB, and write it with PyIceberg … all wrapped in an Lambda.
The idea is … instead of using something heavy like Spark, BigQuery, or Snowflake to ingest data into a Lake House, can we use this extremely light-weight architecture to do the incoming data processing and landing into our “Staging” or “Bronze” layer.
I think we can. This could lead to big cost savings on a lot of Data Platforms. Who needs to spin up a Spark Cluster when we can use a Lambda to ingest data into a Lake House???
The start of the matter.
Here is our Cloudflare R2 data bucket. If you are unfamiliar with data storage on Cloudflare, read here.

Now all we have to do is … (enable Iceberg Catalog on the bucket)
>> npx wrangler r2 bucket catalog enable pickles
✨ Successfully enabled data catalog on bucket 'pickles'.
Catalog URI: 'https://catalog.cloudflarestorage.com/3ee64e77beb1e2c68a3ae7c1cd4d232e/pickles'
Warehouse: '3ee64e77beb1e2c68a3ae7c1cd4d232e_pickles'
Use this Catalog URI with Iceberg-compatible query engines (Spark, PyIceberg etc.) to query data as tables.
Note: You will need a Cloudflare API token with 'R2 Data Catalog' permission to authenticate your client with this catalog.
For more details, refer to: https://developers.cloudflare.com/r2/api/s3/tokens/It’s never been so easy to spend money, just a few commands and you’re off to the races!!
Creating an Apache Iceberg table.
First, we need to get an Iceberg table created in our R2 bucket so our DuckDB has something to work with. Let’s use Divvy Bike trip’s open-source dataset.

The data looks like so …

Nothing fancy really, just some CSV files that have a record for each bike ride taken.
Creating an Iceberg table with DuckDB.
Let’s use DuckDB to create our initial Iceberg table. This will be a little funky because DuckDB DOESN’T HAVE ICEBERG WRITE SUPPORT.
Ops, did I say that too loud?

Part of my job is to be the one that stands up in the midst of the lemmings walking over cliffs saying … “Use Iceberg it’s great, has lots of support … use DuckDB it’s great, the perfect tool for everything!”
This is a perfect example solving problems on the ground in real life, let’s pretend we are a lowly Data Engineer and we have some “super smart boss” who reads LinkedIn a lot all they know is that “DuckDB is awesome and great and so is Apache Iceberg.” We simply have the demand to use these two technologies together, come what may.
We will probably have to use pyiceberg to create the table. If find it highly ridiculous that DuckDB cannot write to Iceberg.

This is one thing you have to love about Cloudflare’s R2 Iceberg setup … it’s unparalleled in the market in terms of ease of use and developer friendly implementation.

As you can see above we had to rely completely on pyiceberg to get the initial table setup. Since DuckDB has no write support.
As you might have noticed our schema for the Iceberg table doesn’t exactly match our raw trip data. This is where DuckDB will come into play in transforming our CSV data and calculating metrics that will need to be rolled up before being deposited in our R2 Iceberg table.
The schema you saw above is for daily metrics.
Writing the code for the AWS Lambda.
First thing’s first, let’s create a basic Lambda that will hold our code and corresponding trigger.

Now we have a wonderful iceiceBaby Lambda with a trigger for any .CSV file that shows up in s3://confessions-of-a-data-guy/iciceBaby/*.csv
So we have our data, we have or Iceberg table ready to go, our blank Lambda with a trigger. Last, but not least, we need the code to ingest a CSV file with DuckDB and then use PyIceberg to write to our table.

Let’s start with the Python code using DuckDB and PyIceberg to do what we want. Let’s write it up and give ‘er the old kick in the pants.
Here’s the steps …
make Dockerfile to hold AWS Lambda code
make ECR in AWS to hold image
make Lambda with trigger (already done)
Here is our simple Dockerfile.
#Dockerfile
FROM public.ecr.aws/lambda/python:3.8.2021.12.18.01-x86_64
COPY . ./
RUN pip3 install duckdb pyiceberg pyarrow boto3
CMD ["main.lambda_handler"]Easy enough. This is how we push it to the ECR in AWS.
#bash
aws --profile confessions ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin 992921014520.dkr.ecr.us-east-1.amazonaws.com
docker build -t iceicebaby .
docker tag iceicebaby:latest 992921014520.dkr.ecr.us-east-1.amazonaws.com/iceicebaby:latest
docker push 992921014520.dkr.ecr.us-east-1.amazonaws.com/iceicebaby:latest
Ok, that’s done. Code next.

I know I’m throwing a lot at you, but that is DuckDB + pyiceberg for us to read a CSV file from s3. What we have going on is …
read the file with DuckDB from s3
run the GROUP BY analytics with DuckDB
convert the result to Arrow
use PyIceberg to connect to the R2 Data Catalog
use PyIceberg to the Iceberg table via Arrow
Aren’t you excited to know what happened?

Apparently this is a think with DuckDB and Lambda runtimes.

Word is if we set `HOME=/tmp` or something of like in the environment, all will be well. I went ahead and added this …
import os
os.environ['HOME']='/tmp'Well, look at that. Success! If we go read out Iceberg table in Cloudflare’s R2, we have data!
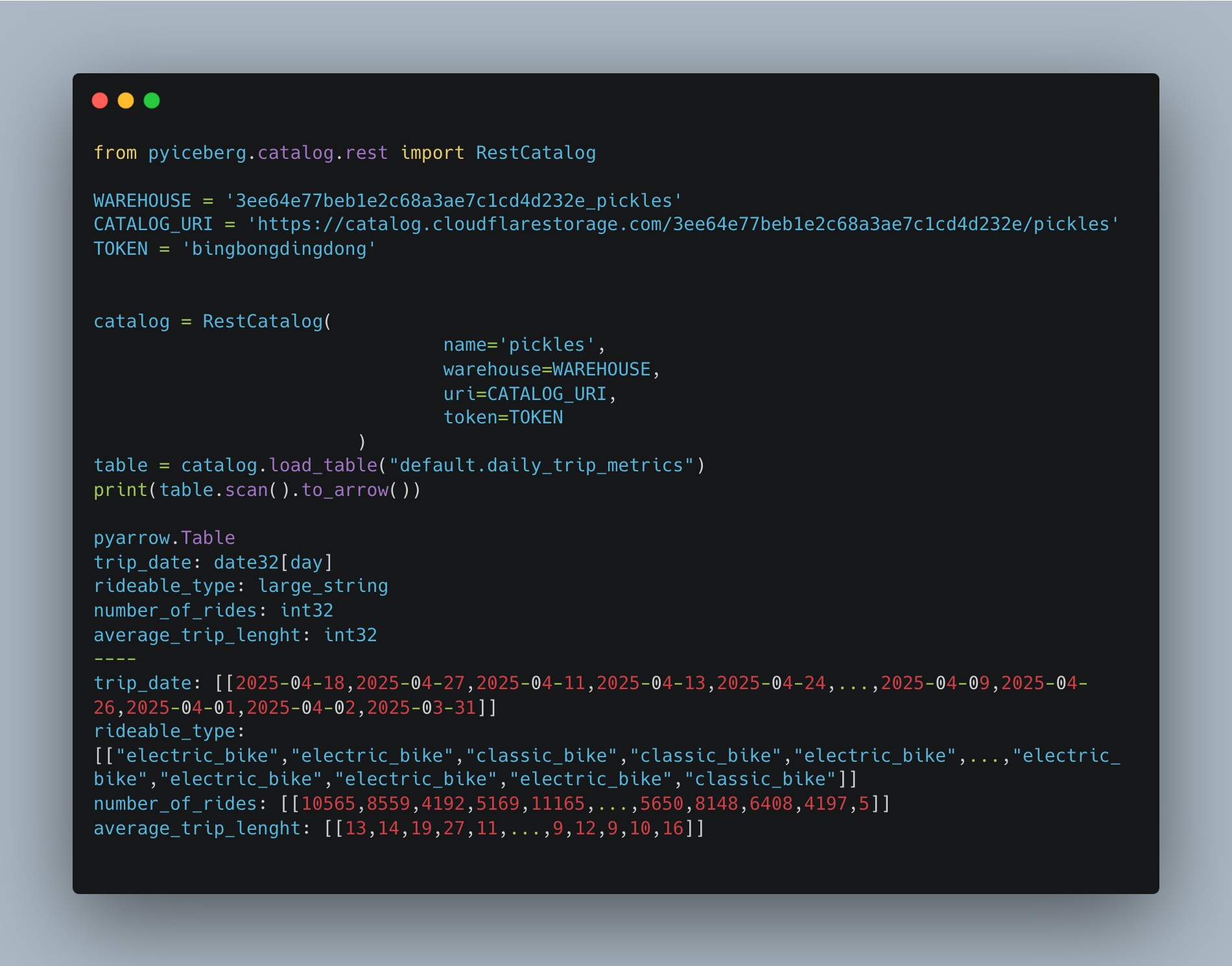
Not going to lie, I didn’t think it was going to be that easy. I lay most of that ease at the feet of Cloudflare’s R2 Data Catalog setup.
It’s dead simple to use and setup, unlike most other options that are overly burdensome.
The DuckDB code itself is neither here not there, I find it perfectly acceptable although a little mundane. There is no doubt that the SQL god’s who have bewitched the minds of all Data Engineers for decades, have served us this delicious DuckDB knowing that we could never keep our fingers from its little tricks.
The real pain here is dealing with pyiceberg, connecting to catalogs, connecting to tables, having to use that simpering middleware to write to our Iceberg table. Simply unacceptable.
We need first class Iceberg READ and WRITE support in all major data tooling, no exceptions. I need no catalog to read or write from a Delta Table if I so choose.
I will leave it here.
To put this to bed, for me the hour is getting late, I think that we’ve proved a few things here.
It’s possible to build light weight Lake House data processing.
AWS Lambda is underutilized.
DuckDB is fast and versatile, easy to use.
Cloudflare’s R2 Data Catalog for Iceberg is an unsung hero.
pyiceberg and the Iceberg Catalog requirements are an achilles heel.
I’m old and crusty but can learn new tricks.