



Weap and moan all you keyboard jockeys, you simple peddlers of code. Your doom and what you feared greatly is coming to pass. You’ve been replaced.
At least that’s what the AI pundits are saying about the new o1 OpenAI model that apparently blows the socks off the previous 4o model when it comes to programming and other benchmarks.

I’ve been trying to ride down the middle of the tracks when it comes to AI and programming. I’ve been writing code and doing Data Engineering long enough to see the obvious flaws in the current AI models. I’ve also embraced AI into my development lifecycle for probably 2 years now.
This has left me pessimistically optimistic if there is such a thing.
AI has been frustratingly stupid when it comes to anything beyond simple code, BUT, it has also increased my efficiency as a programmer by at least %30, plus or minus, depending on the project.
I’m very curious to put this new AI model to the simple Data Engineering test.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

Putting OpenAI’s o1 to the Data Engineering test.
Now that this new and improved o1 model is out and supposedly a next-level programmer compared to previous models I think it’s time we kick the tires together.
But, I want to do something outside the box … yet simple enough to be a basic Data Engineering task. It’s a fine line to walk.
I’m going to treat OpenAI o1 like I would a Junior Data Engineer. We are going to pretend we are having a problem with performance in PostgreSQL … and we need the Junion Engineer to set up an end-to-end test to prove what the fix should be.
Here’s the challenge.
So here is the sample problem we are going to have o1 work on. This is based on an actual real-life problem I fixed recently. This problem will serve two problems …
can OpenAI’s o1 solve query performance information without telling it what the solution is.
once we get the model on the right track … can the model HELP us to create an end-to-end test?
aka, generate DDL, table data, queries to test etc.
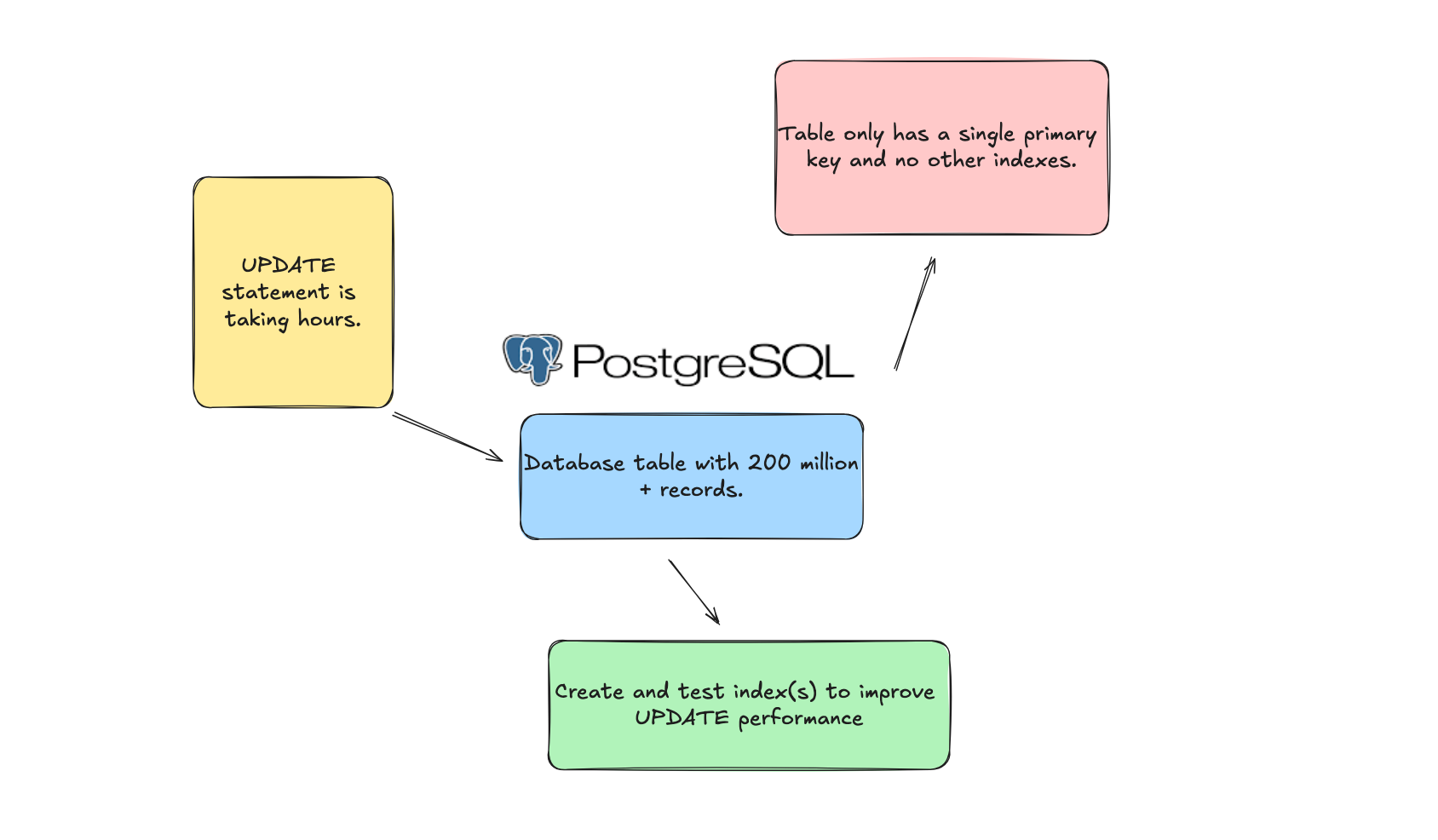
This is what I would consider a very basic Data Engineering problem, something I would expect a Junior Data Engineer to be able to tackle, solve, and design a test that can be run outside Production to prove the proposed solution works.
Postgres table with
200 million100 million + recordsUPDATE statement has been running slow
Inspection of indexes on the table shows only a single primary key
Proposed solution to add an extra index and test end-to-end to prove our idea
Ok, so next let’s just dive into the problem at hand and see how o1 does. I will show the questions I ask it and the responses etc, including where, if anywhere, it flubes.
Diving into OpenAI o1.
So let’s get our first prompt written up.
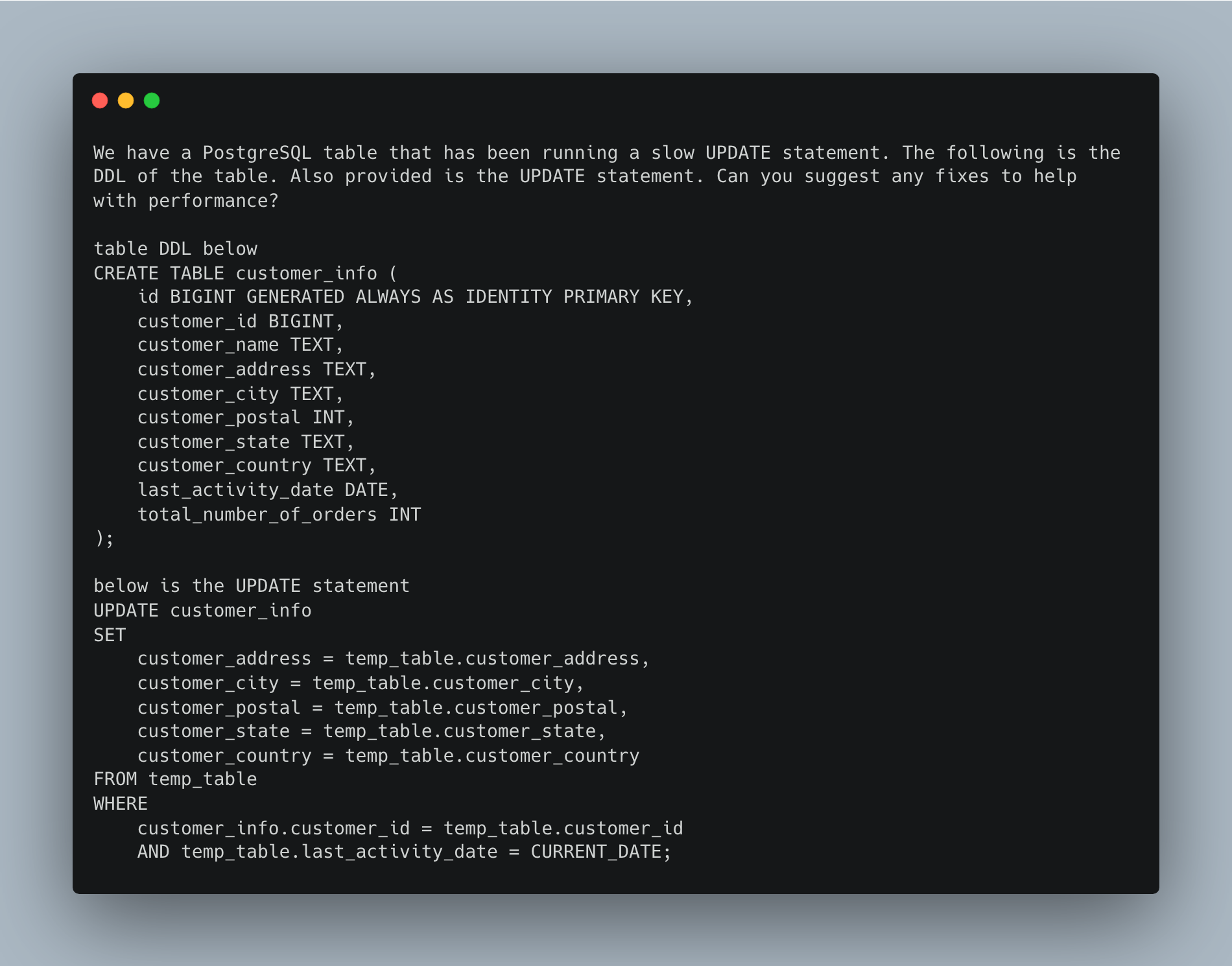
Ok, I’m not even sure where to start with the response. It’s intense and large. I will include the whole response in the companion YouTube video.
But, the o1 model does at least provide a summary at the end.

Let’s continue down the road that we are dealing with a Junion Data Engineer and go down the track that o1 gave us to use indexing to improve the performance.
Here is what OpenAI’s o1 tells us to do …
1. Add Indexes on Join and Filter Columns
a. Index on customer_info.customer_id
Since you're joining customer_info and temp_table on customer_id, adding an index on this column in the customer_info table can significantly speed up the lookup:
CREATE INDEX idx_customer_info_customer_id ON customer_info(customer_id);b. Index on temp_table.customer_id
If temp_table is large, creating an index on customer_id in the temporary table can also help:
CREATE INDEX idx_temp_table_customer_id ON temp_table(customer_id);Note: For temporary tables, indexing might not always be beneficial due to the overhead of index creation versus the time saved during the update. Evaluate the size of
temp_tablebefore indexing.
c. Index on temp_table.last_activity_date
If temp_table contains a large number of records with varying last_activity_date values, indexing this column can help filter the records more efficiently:
CREATE INDEX idx_temp_table_customer_id ON temp_table(last_activity_date);Let’s go for it …
I mean it is going down the right road I think. I did like that the answers o1 gave were wide-ranging… that is part of the best use of AI in programming, listen to its ideas … make sure you are thinking outside the box and considering all options.
Remember, we want the AI to prove what it’s doing by setting up test, so let’s ask it to generate the 200 million + sample data.

Not bad, seems pretty legit.

Before we put this OpenAI o1 solution through the wringer, I’m going to set up an AWS RDS instance. I know a lot of milk toast programmers try to use local stuff like Docker, which is sometimes ok, but I also want to test this in a REAL environment.

I highly suggest you do the same, set up a personal AWS account and use it to learn and test things. Honestly, if you don’t set up much stuff and delete it when you're done … your bill be less than what you spend on coffee.
Well, now that I’m done typing my RDS instance is available.

Time to run that SQL to create the database tables, and once that is done start to populate the main table.

It appears that the Python script to generate the 200 million records is working like a charm … albeit a slow charm. I checked the database using a count on the table and could see it slowly ticking up.
postgres=> SELECT COUNT(*) FROM customer_info;
count
--------
260000
(1 row)
postgres=> SELECT COUNT(*) FROM customer_info;
count
--------
270000
(1 row)
postgres=> The next thing we will need to make this test work is to create another table, same as the above, and call it customer_info_tmp, and we will copy … say … 6 million records from our customer_info table over to it?
This will allow us to run the UPDATE statement …
one as is to see the performance (aka no indexes created beside the default primary key)
again after the indexes are created
Moving on.
Ok, so first things first to report, the code that o1 gave us to populate 200 million records into the Postgres database was probably the slowest thing ever written on the face of the earth.
It took over 24 hours before I finally killed it …
postgres=> SELECT COUNT(*) FROM customer_info;
count
-----------
116170000
(1 row)We got over 100 million records and that is just going to have to do. So, we’ve learned just in the beginning phase here at OpenAI’s supposed programming savant cannot do well when trying to populate records from Python into Postgres SQL in a reasonable manner.
(aka it must struggle to understand scale out of the box)
This is an interesting finding, I wonder if it’s a harbinger of things to come or not.
Ok, so now I’m going to setup the temp (second) table and put 6 million records into it.
INSERT INTO customer_info_tmp
(customer_id,
customer_name,
customer_address,
customer_city,
customer_postal,
customer_state,
customer_country,
last_activity_date,
total_number_of_orders)
SELECT
customer_id,
customer_name,
customer_address,
customer_city,
customer_postal,
customer_state,
customer_country,
last_activity_date,
total_number_of_orders
FROM customer_info
LIMIT 6000000;
postgres=> SELECT COUNT(*) FROM customer_info_tmp;
count
---------
6000000
(1 row)So we got our two tables, one with 100 million+ records, the other with 6 million. Now, let’s run the UPDATE statement WITHOUT indexes just to get a baseline on how slow that might be.
Here it is … and we will put it inside some Python to get a time.
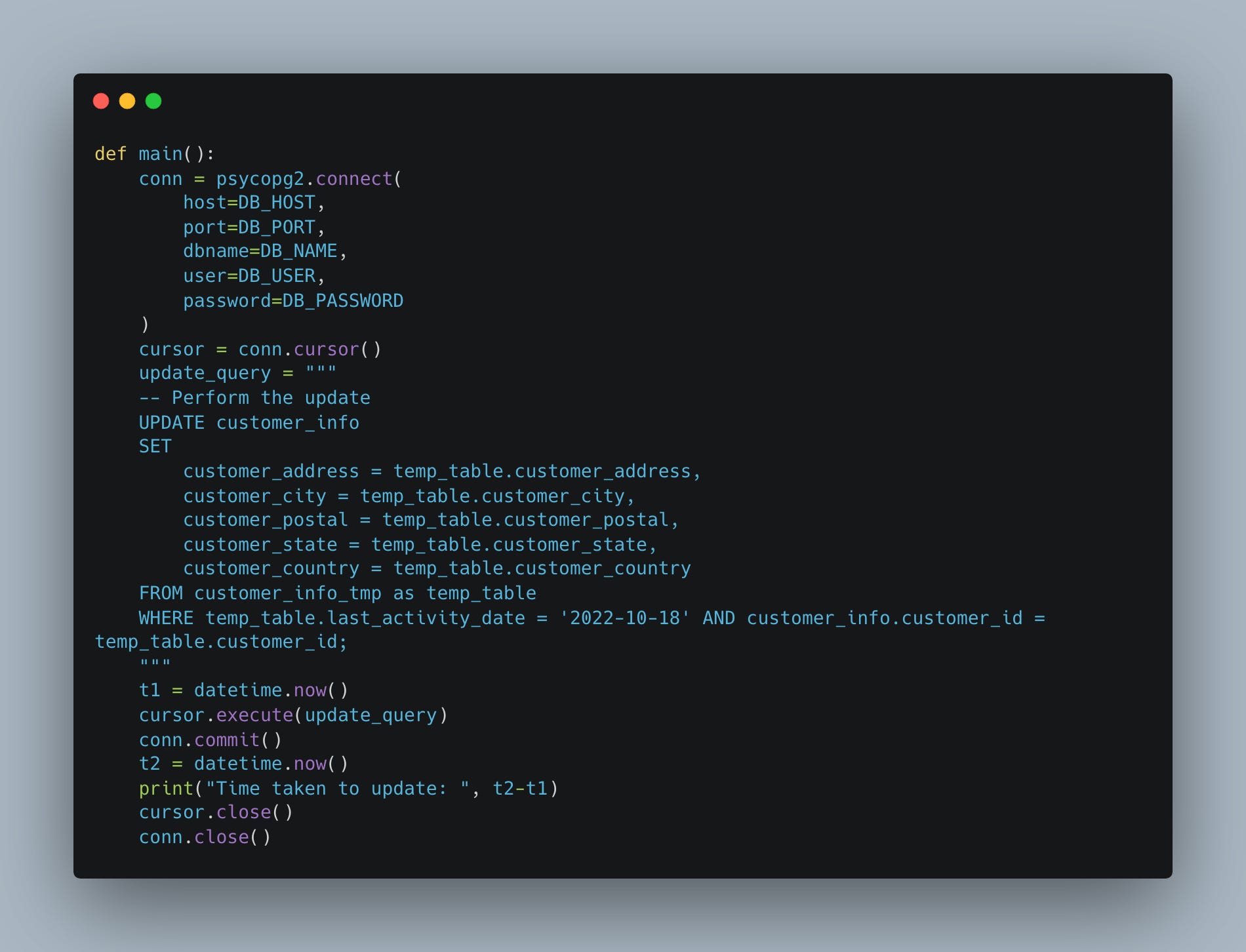
Well … that did take some time, but not terrible ~2 minutes.
Time taken to update: 0:02:00.890669And remember that OpenAI o1 suggested two different indexes as well, so including the indexes we’ve seen above, it wanted …
CREATE INDEX idx_temp_table_last_activity_date ON customer_info_tmp(last_activity_date);
CREATE INDEX idx_temp_table_customer_id ON customer_info_tmp(customer_id);… on both tables just to be safe.
(There are only 8k records getting updated.)
postgres=> SELECT COUNT(*) FROM customer_info_tmp WHERE last_activity_date = '2022-10-18';
count
-------
8228
(1 row)So now that we have the two separate indexes on each table (customer_id and last_activity_date) … let’s re-run the example same query.
Time taken to update: 0:00:08.580337That’s a BIG difference for sure.
Looks like OpenAI’s o1 model came through for us, cutting the query down from 2 minutes to 8 seconds with its suggestion for adding the indexes.
Thoughts on AI for Data Engineering.
Don’t worry, I hail from the group who things it’s not the end of the world for Software Engineers when it comes to AI, but, that being said, I’m also not going to ignore what’s happening in the AI world as related to code and Data Engineering.
I think we proved, maybe or maybe not, that OpenAI’s o1 model is at least a Junior Level Data Engineer don’t you think? Sure, probably some mistakes here and there (not being able to write a scalable way to ingest a few hundred million fake records into Postgres), but at the same time hitting the nail on the head with the index suggestion to increase runtime of a UPDATE query.
What I think the takeaways from this test should be …
AI will not take a good Data Engineers job anytime soon
newer AI models can probably solve most problems as well as any Junior Data Engineer
they will probably speed up your troubleshooting time (by summarizing ideas you would have found on Google)
you should try to include AI in your developer workflow to increase your efficiency