

Introduction to Daft ( ... vs Polars)
Distributed DataFrames for Python (built with Rust)


It’s been a while since I’ve kicked ye ole’ tires on something new. You know how much I love to pick and poke at things, I just can’t help it. But this one didn’t take any convincing on my part. I couldn’t even tell you where I ran into it.
Daft that is.

Part of me said … seriously, another Python DataFrame library? How we could possibly add another one to the list? And, why have I never heard of it?
But, then I saw it was built with Rust. Well, that changes things. Maybe? We have Polars, but not Polars distributed … yet. Is this another takeout shot on PySpark? Good luck with that.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

I think I’m getting ahead of myself. Nice and easy does it.
High-Level Overview of Daft
Well, let’s start from the top.
“Daft is a fast and scalable Python dataframe for Complex Data and Machine Learning workloads.”
Typical of pretty much every Python Dataframe package since the beginning of time.
Polars
Ray
Dask
etc …
It’s always the same old story I guess. Everyone wants to create the next Apache Spark, can’t blame em`.
What does Daft say about itself?
Offers UDF operations on Dataframes
Integration with other ML/AI tools like Ray etc.
Goes from local to the cloud seamlessly
Can run on a distributed cluster
Built with Rust
Build on Apache Arrow
This sounds nice, and it also sounds like Polars, except for the distributed part. That’s probably one of the most annoying parts of Data Engineering.
If you want reliable distributed Dataframes the only option is PySpark, everything else people try to laud is typically just not that reliable and falls apart once you do something *crazy* … like read files from s3 <insert eye roll>.
Anyway, enough moaning. Let’s try Daft (and compare it to Polars)
Trying out Daft.
I’m not sure what I’m expecting to learn by trying out Daft, but if we don’t, then I guess that is learning something. First things first, when I’m doing work like this I usually set up a Git repo and a Docker setup that container that has what I need.
The first thing you should always try.
I’m a firm believer in trying out the easy stuff on the bat, for a few reasons. If a tool can’t do something basic like read files from s3 using environment variables … then it’s probably not a good sign of things to come.
That being said, let’s see if Daft can read CSV from s3 using env creds. (we are using Divvy Bike Trip open-source dataset)
export AWS_ACCESS_KEY_ID=xxxx
export AWS_SECRET_ACCESS_KEY=xxxxxxxx
export AWS_DEFAULT_REGION=us-east-1
>> import daft
>> df = daft.read_csv("s3://confessions-of-a-data-guy/*.csv")
>> print(df.collect())
I’ll take it. Pleasant surprise. You have no idea how many so-called great tools can’t even do something simple like this without many various gyrations.
If you are an astute observer, you might have noticed something about the above Dataframe printed out. Take a second look, do you see it?
It did a very good job of picking up on the DataTypes, aka it got them all correct. Impressive.
You know what the real question is. Can Polars do this? Let’s give it a try.
>>> import polars as pl
>>> df = pl.scan_csv('s3://confessions-of-a-data-guy/*.csv')
>>> print(df.collect())
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.12/site-packages/polars/lazyframe/frame.py", line 1855, in collect
return wrap_df(ldf.collect(callback))
^^^^^^^^^^^^^^^^^^^^^
FileNotFoundError: No such file or directory (os error 2): s3://confessions-of-a-data-guy/202401-divvy-tripdata.csvThat’s a no so far. Let’s try `read_csv` instead of `scan`. Nope.
>>> import polars as pl
>>> df = pl.read_csv('s3://confessions-of-a-data-guy/*.csv')
>>> print(df.collect())
ImportError: Install s3fs to access S3Ok, so we can `pip install s3fs`, no problem. Try again.
raise FileNotFoundError(
FileNotFoundError: [Errno %s not found. The URL contains glob characters: you maybe needed
to pass expand=True in fsspec.open() or the storage_options of
your library. You can also set the config value 'open_expand'
before import, or fsspec.core.DEFAULT_EXPAND at runtime, to True.] confessions-of-a-data-guy/*.csvCome on Polars, it’s not that hard, Daft can do it. Seems like with Polars we have to resort to `pyarrow` to help us get it done.
import polars as pl
import pyarrow.dataset as ds
dset = ds.dataset("s3://confessions-of-a-data-guy/", format="csv")
(
pl.scan_pyarrow_dataset(dset)
.collect()
)
Good on Daft for getting it done right.
Also, the smart ones among you would have also noted that I’ve been using `collect()` by default with Dask because ….
“This is because Daft is lazy and only executes computations when explicitly told to do so.”
Let’s do a simple little performance test of Daft vs Polars, and in the process learn how Daft handles simple queries on Dataframes like some GroupBy and Aggregation.
I’m thinking of making this Polars vs Daft a little interesting, make ‘em both work at it, we should GroupBy year, month, and day (forcing them both to do a little extra work) … as well as member type, and then count the number of rides, and the Sort that output.
Simple enough, yet under the hood, enough work to make those engines sweat.
Start with Daft …
import daft
from daft import col
from datetime import datetime
t1 = datetime.now()
df = daft.read_csv("s3://confessions-of-a-data-guy/*.csv")
df = df.with_column("year", df["started_at"].dt.year())
df = df.with_column("month", df["started_at"].dt.month())
df = df.with_column("day", df["started_at"].dt.day())
df = df.groupby(["year", "month", "day", "member_casual"]).agg(col("member_casual").count().alias("count"))
#df = df.sort(by=["year", "month", "day"])
print(df.collect())
t2 = datetime.now()
# print how long it took
print(t2 - t1)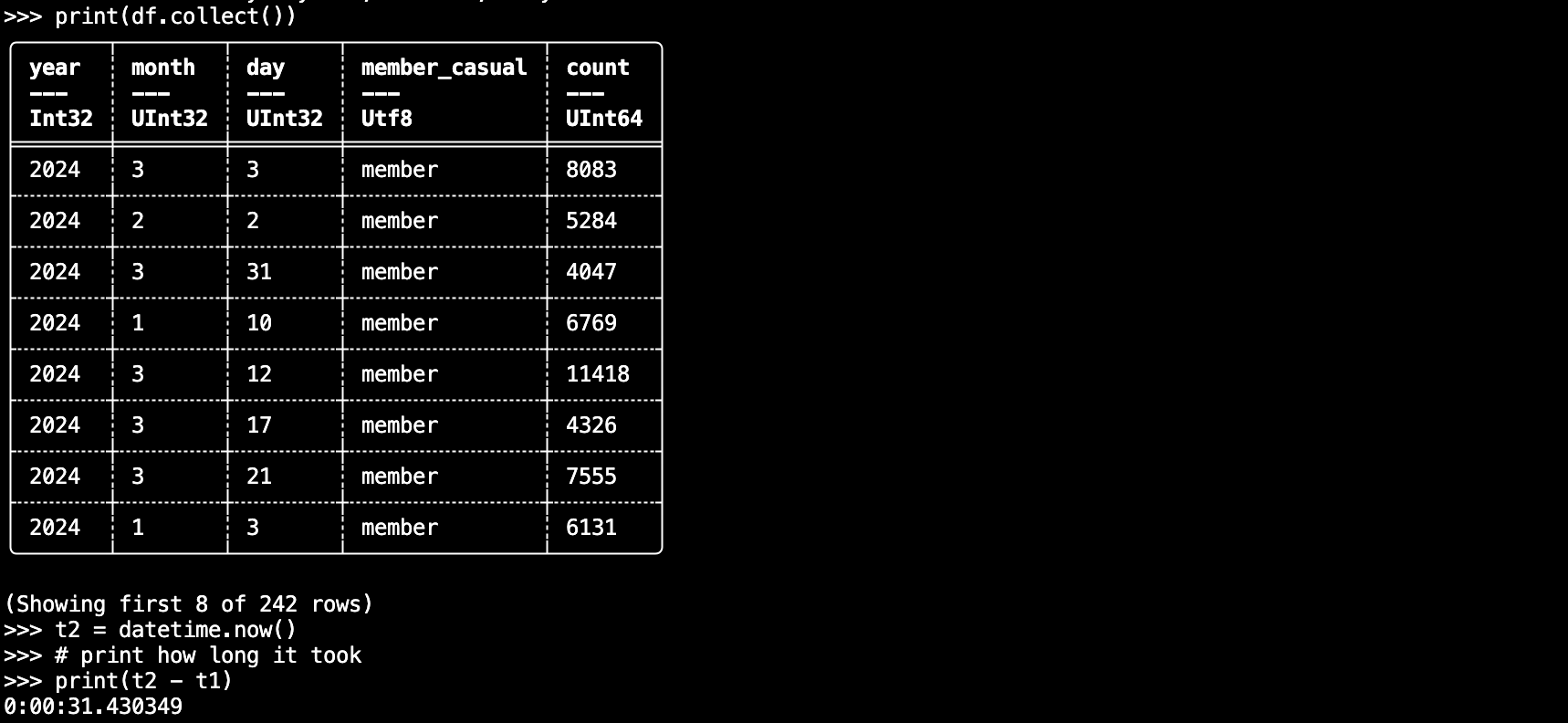
About 31 seconds, just to be clear, this data has about 1,084,749 records, not very much.
Let’s do this in Polars.
import polars as pl
import pyarrow.dataset as ds
from datetime import datetime
t1 = datetime.now()
dset = ds.dataset("s3://confessions-of-a-data-guy/", format="csv")
lf = pl.scan_pyarrow_dataset(dset)
lf = lf.with_columns((pl.col("started_at").dt.year()).alias("year"))
lf = lf.with_columns((pl.col("started_at").dt.month()).alias("month"))
lf = lf.with_columns((pl.col("started_at").dt.day().alias("day")))
lf = lf.groupby(["year", "month", "day", "member_casual"]).agg(pl.col("member_casual").count().alias("count"))
lf = lf.sort(by=["year", "month", "day"])
print(lf.collect())
t2 = datetime.now()
# print how long it took
print(t2 - t1)
Interesting, unsurprisingly Polars took 45 seconds, about 15 seconds longer than Daft. That doesn’t surprise me because we are mixing two libraries to make Polars do what Daft is doing behind the scenes reading the s3 CSV files.
Honestly, the syntax is about the same, although I think Daft is slightly cleaner.

Distributed Daft
One of the features that first drew me to Daft was the allure of being distributed. After doing this work, reading the docs, etc, I couldn’t really find any mention or quick guide to disturbed Daft, a little disappointing.
I feel like they tricked me.
Looking closer at what it says you CAN distribute Daft with other tools like Ray. I see. I’m not sure if that’s the same thing in my book, but we can give them the benefit of the doubt.
This is interesting because you can setup Ray Clusters on Databricks, they have support for that, so if you’re interested you could in theory run something like Daft on Databricks, assuming you can get enough speedups to beat PySpark with Daft to make it all worth it.
That sound worth my time to test, but I’m running out of time, so let’s leave that till next time.
in your aggregate test, it does not appear that the sort for Daft is working.
The fact that daft out of the box can read from s3 without the extra hoops to jump through is a win. Polars and duckdb need to get with the times and make s3 and gcs first class directories