

Polars and DuckDB release Unity Catalog (Delta Lake) integrations. Who lied? Who didn't?
... say it ain't so ...


You know, just when you think things have finally settled down and our poor ears won’t have to hear another thing about The Great Catalog War, or The Great Lake House Format War … it just keeps rolling in.
As much as I hate to admit it, it appears Catalogs are indeed becoming essential and core to most modern, and future, Data Stack being built and used.
For example, if you are using Databricks as your main Platform for data storage and processing < insert Iceberg and Snowflake if you please > , if you are uncreative in nature it means you have a one track mind that consists of you using Spark inside Databricks to do EVERYTHING with your Delta Lake tables.
This can be a hard road if you have anything approaching a normal Data Platform that churns and burns data from a variety of sources and sends data back out to variety of downstream processes and systems. Rarely is the data world we move in black and white. So, with that being the reality, there are many use-cases that force us to get creative when we THINK our only option is to use a Databricks Job or heaven forbid a notebook.
In the past, choosing a particular platform “locked you in” into that vendor.
With some gyrations and throwing salt over your left shoulder at midnight could you manage to extract yourself and your data for some specific use case that didn’t work with that big old beast Spark.
I think most vendors, after too many years, finally came to realize that customers demanded more flexibility.
We have multiple tools
We have multiple clouds
We have multiple use cases
We have multiple data sets
So, our loving vendor overlords gave us a solution. Catalogs. One of those titians vying for supremacy is Unity Catalog.

I’m not going to spend time getting into the discussion of WHAT exactly is a Catalog, it’s pretty much self explanatory. If you want it explained like a 5 year old, it’s a one stop storefront where you can get all your data.
The announcements start rolling.
Of course with all this development around catalogs, like Unity, gaining so my attraction and attention (you can’t simply write off the fact that most ALL Databricks users have massive amounts of data stored in Unity Catalog Delta Tables), general open source tools are starting to adopt and provide interfaces for catalogs, like Unity.

Now, before we get into testing this new features. I want to mention that you could still typically use these tools to interact with “Unity Catalog based Delta Lake” tables … it just took a little ingenuity.
Below is a snippet of code that is actually used in Production , for over a year, to interact with a Unity Catalog Delta Lake table, long before any Unity Catalog integration was released.
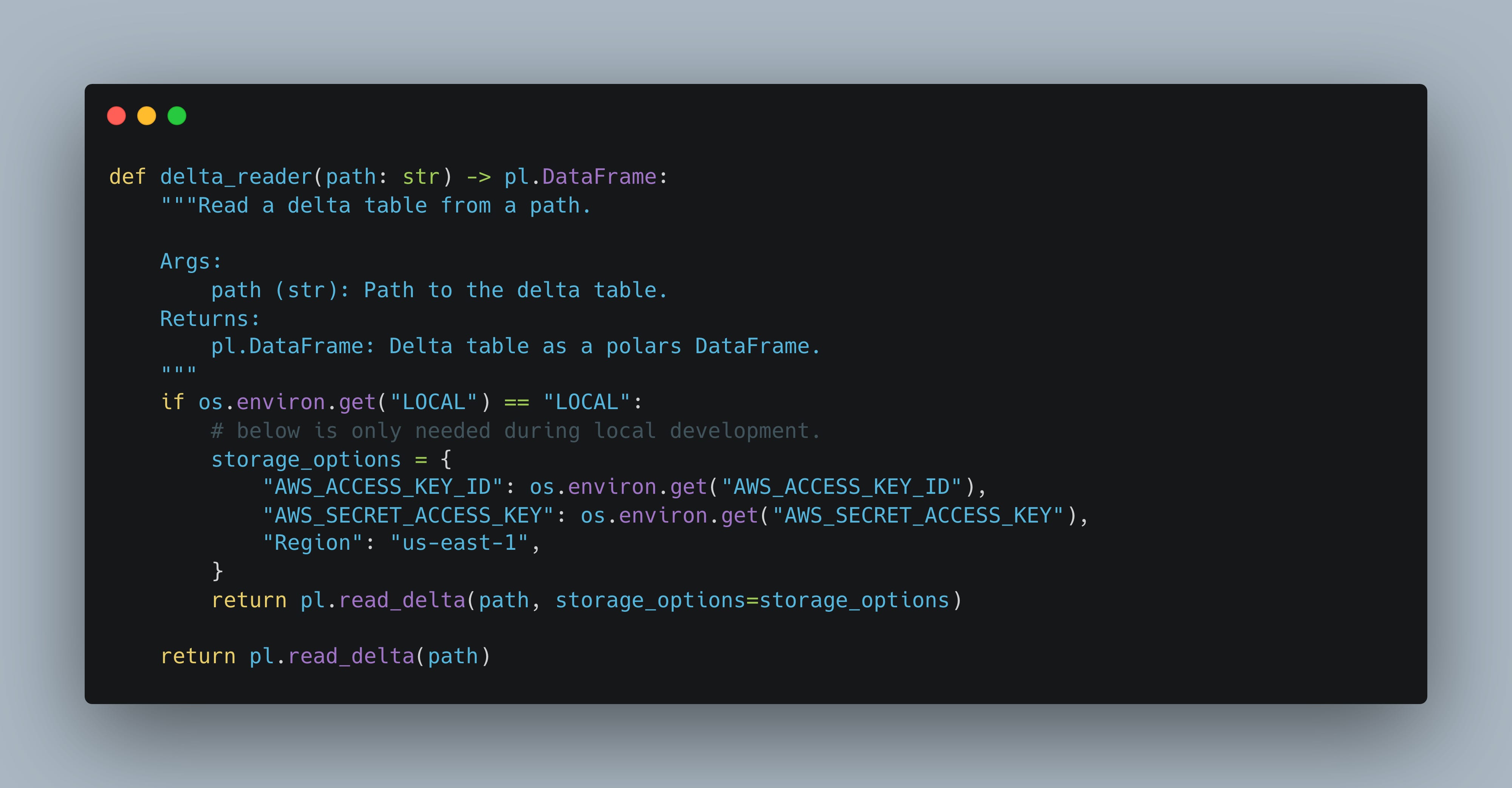
Basically if you knew the “backend” storage location of a certain Delta Lake table in Unity Catalog, you could do what you needed today. This sort of workflow is sorta a pain, espeically when table locations could change, and needing to find the physical location beforehand.
It’s time now to test if this new experimental integrations from DuckDB and Polars are real or not. Did they lie to us? You know they better have at least tested them before you know I will take them to task if they don’t at least minimally work.
Testing Polars new Unity Catalog integration for Delta Lake tables.
So, let’s see if this code can be much simplified, let’s write a simple data pipeline using Polars + Unity Catalog and see what happens.
First thing to note is that the documentation sucks for Polars and Unity Catalog. I’m not sure if that is because things are unstable and they are waiting for things to solidify? Either way you can find minimal documentation of the code here.

I was able to get a simple data pipeline running. I have to admit, it did make the interaction with a Unity Catalog Delta Lake table much more simple and straight forward.
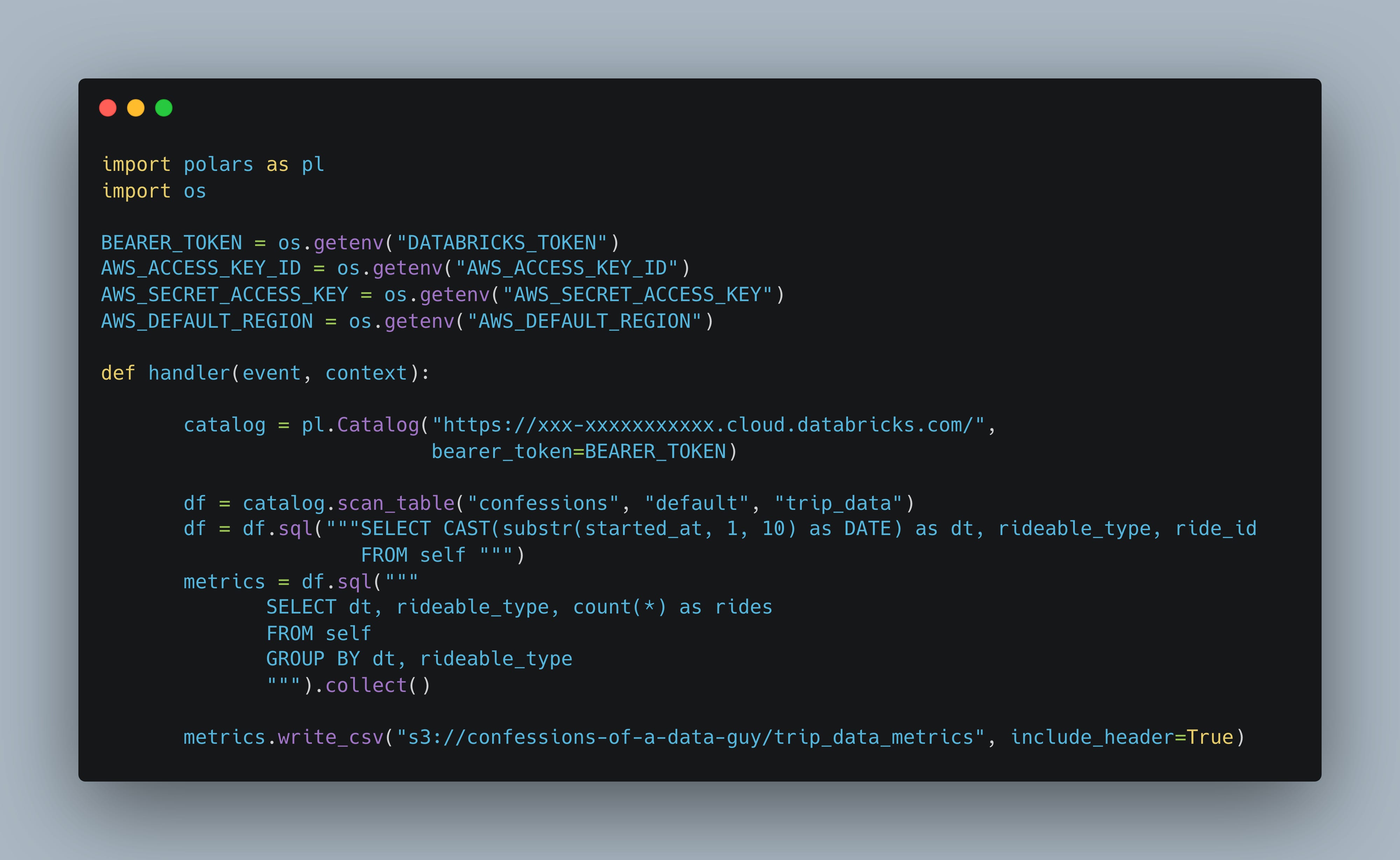
Very seamless indeed.
Basically all I needed to use this new Polars Unity Catalog feature was …
a call to Catalog()
URL of the Unity Catalog (Databricks or Open Source)
Databricks access token
understanding of
Catalog
Schema
Table names
For example once you call pl.Catalog("https://xxx-xxxxxxxxxxx.cloud.databricks.com/",bearer_token=BEARER_TOKEN)
You can scan any Delta Table into a Lazy Frame if you know the FULL name … catalog.schema.table
df = catalog.scan_table("confessions", "default", "trip_data")
Of course as a side note, with Polars you can ran SQL, like I did, on your LazyFrame representing your Delta Lake data in Unity Catalog, do as you like, and push the results somewhere.
It looks there isn’t much for functionality yet inside the Polars Unity Catalog integration, but at this point it seems to be pretty early on. The scan_table seems to be about the only real useful thing provided yet … what we really need is a write_table.

I tested my code both inside a Databricks Notebook AND inside an AWS lambda, both worked great. Kudos to Polars to actually building something that works.
Testing DuckDB’s new Unity Catalog integration for Delta Lake tables.
Now, let’s head on over to DuckDB and see if they can also live up to their word in the same fashion as Polars. The DuckDB extension for Unity Catalog seems to have been around a lot longer, and actually has more documentation, from both DuckDB and Unity, so I’m expecting a lot out of them.


Let’s try it on a Databricks Notebook first, something running inside the Databricks Environment will hopefully make things less complicated and more likely to work?

Surprise surprise, no luck with this.

This is a strange error indeed. My catalog doesn’t exist? Well of course it does, we used that catalog to run the Polars code just fine.
After looking through more documentation a little harder, it appears I might have to manually attached my “catalog” to DuckDB? Strange.

I tried this, but still got a different error.
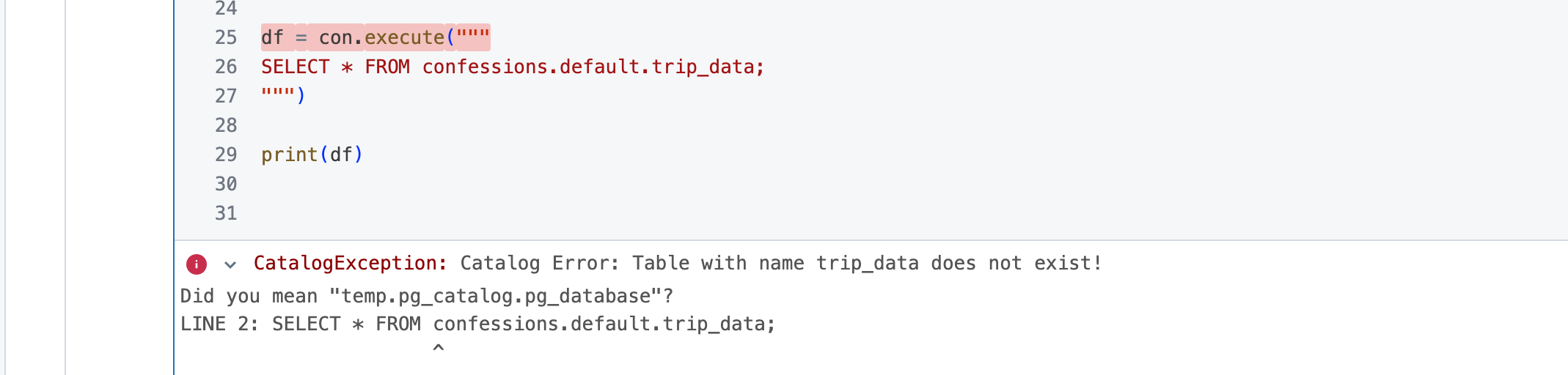
It was now saying my table doesn’t exist, which it does, which makes me wonder if I went down the right road with the Catalog attach thingy.
After some research it appears that I’m not the only one having this sort of problem. There appears to be a open GitHub issue about this sort of thing open for like half a year. Surprise surprise. We ran into this same sort of thing with DuckDB and OOM issues.

I tried everything I could, simply couldn’t make DuckDB read a Unity Catalog Delta Lake table. Liars.
I’ve come to like DuckDB more and more lately, it’s ability to read remote JSON files for example and flatten them into a tabular structure is sliced-bread. But, I do frequently run into these issues (like large than memory datasets) with DuckDB where it’s like “it works on my machine, why not yours??”
Catalogs are the future, get with it people.
Honestly, tools need to get with it, like Polars did. Heck, Daft has had the GOAT integration with Unity Catalog Delta Lake tables for a long, long time.

The more time that goes past, the more people migrate and start to use tools like Databricks and Unity Catalog, more and more data is being stored behind these Catalogs … there are workaround, but many times they aren’t that fun and people are lazy.
If your tool doesn’t stay up-to-date with the times, people will simply use other tools to do the work, in this case use Polars instead of DuckDB.
Sure, you can fix a thing, but by the time you have fixed it people have moved on and simply settled on other ways to solve the problem.
And you are going to get up on a stage and title a YouTube video “Announcing DuckDB support for Delta Lake and the Unity Catalog extension” … then you should probably make sure that the Unity Catalog extension at least nominally works for the most basic use case INSIDE A DATABRICKS NOTEBOOK.
Anywho. I’m sure the internet is full of people who will shortly tell me I’m and idiot and what I did wrong. Thank the Lord for them people eh?
Either way I just approached the problem simply as any other engineer would and took what information and documentation they provided at face value and gave it a shot.
Polars worked. DuckDB didn’t.
You're an idiot
Calling the maintainers of a library you claim to enjoy a lot liars simply because you couldn't get a very early-stage prototype feature to work in your environment is quite heavy-handed. It does less to insult the maintainers than it does expose your lack of ability and professionalism. It's okay to say "this didn't work for me" but all-out accusing the team of straight-up lying about a feature is borderline slanderous, and makes it seem like you might be an awful person to work with. I get that this "no holds barred" thing is your vibe for engagement purposes, but have some respect for the people who build and maintain the tools you (ungratefully) use day-to-day. We're standing on the shoulders of giants here, not stepping on their faces.
Next time something doesn't work the way you expect, make an issue on github. Or maybe consider contributing a fix yourself instead of leeching on others' work for likes.
Unsubscribe