

Revisiting Data Quality
options?


Oh, that age-old topic of Data Quality, often discussed but never implemented. Poor little blighter. Who knows what it’s like to be the old, beat-up rock that always gets kicked, gets no love or attention, just told about everything you do wrong (try writing a Substack like me, you’ll find out quick enough).
That is Data Quality, isn't it?
The age-old question.

And the age-old answer.

Nothing could be truer and to the point.
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Content like this would not be possible without their support. Check out their website below.

Data Quality isn’t cool enough.
I’ve written about Data Quality a few times over the years; it’s simply not a popular or sexy topic. Always mediocre reaction to mediocre tools that don’t work well.
Truth be told, Data Quality is something CTOs and Data Leaders love to talk about, but when you ask them to either pony up some money for a tool, or pay some engineers for work on this topic for a quarter or two, you get mumbling, muttering, and a general waving of hands. Then it’s back to business as normal.
It’s always sight out of mind, the old nagging suspicion in the back of the head. Random data problems that pop up and get fixed. Not enough pain to actually do a thing.
BTW, here are some past DQ articles.
A Gentle Introduction to Data Quality.

Data Quality came out of nowhere this year, you would think after decades of building Data Warehouses, Data Lakes, and Data Platforms that the data community would have committed itself to Data Quality (DQ) about 10 years ago.
Primer on Data Quality

Mmmmm. This is one topic we hear a lot about, sure maybe not as much as Polars or DuckDB, but it’s like a continual dripping of water, the humdrum of “get better with your Data Quality,” never ends.
Data Quality with Databricks Labs new DQX tool.

I recently saw something pop into my LinkedIn feed that made me pee and scream simultaneously. An announcement from Databricks Labs about a Data Quality tool specifically designed for Spark PySpark Dataframes.
Data Quality in the Lake House era
What is Data Quality in the Lake House era? It’s a mess, is what it is. We Modern Data Engineers were spewed forth from the mouth of the Data Lakes, jumbles of data piled into stacks, with rigidity to match that haphazard approach.
We landed in the detritus of Lake House architecture, made up of Iceberg and Delta Lake. Somehow reminding remenicent of the old SQL Server days, yet different in many ways. Less rigid, schema evolution is no problem. Do what you want; the Lake House is a forgiving master.
It’s sorta like being your own boss. You’re nice to yourself. You say, “We don’t need any stinking constraints,” or “Go ahead and add those columns, no problem.”
loosey goosey approach to data modeling
constraints are for Postgres, not Iceberg/Delta
we add or change columns willy-nilly

We spend all our time optimizing pipelines to save money on that giant cloud bill. No time to work like a filthy peon and worry about DQ issues; we can solve them as they come.
In the end, we are all victims of our collective sins. We never think the piper will come to collect his pound of Data Quality flesh.
Anywho, enough pontification, let’s get to the matter at hand. Say we WANT to do a little extra in the field of Data Quality in our Lake House. What are our options? What should we do?
Data Quality Baseline for the Modern Lake House
I have a feeling that I’m already going to sound like your Mother standing over you, shaking my finger at you, saying, “Clean your room, you filthy ingrate, who wants to live like this?”
Yeah, well … it’s true.
Of course, when we think about Data Quality, our minds go straight to an open-source or SaaS product that promises to solve all our problems. This is maybe 50% true, or less.
We should start by introspecting our data. Data Quality starts right here at home.
Contrary to popular belief, Data Quality starts with simply having a “handle on your data.” What does that mean? Well, not everything is a STRING. Not everything can be NULL.

You can’t build (or shouldn’t) Data Quality with a shaky foundation. You need to understand and therefore control the incoming data. Most Data Quality “issues” come from a poor understanding and lax approach to data. Start small.
Schema ← data
Constraint ← data
Testing ← business logic
Everyone is capable of doing this. You should use the schema of your data store to your advantage, squeeze every last drop out of it, Postgres to Delta Lake to Iceberg, you have a tool before you.
Schema
Let’s start with the schema, and make this very clear.
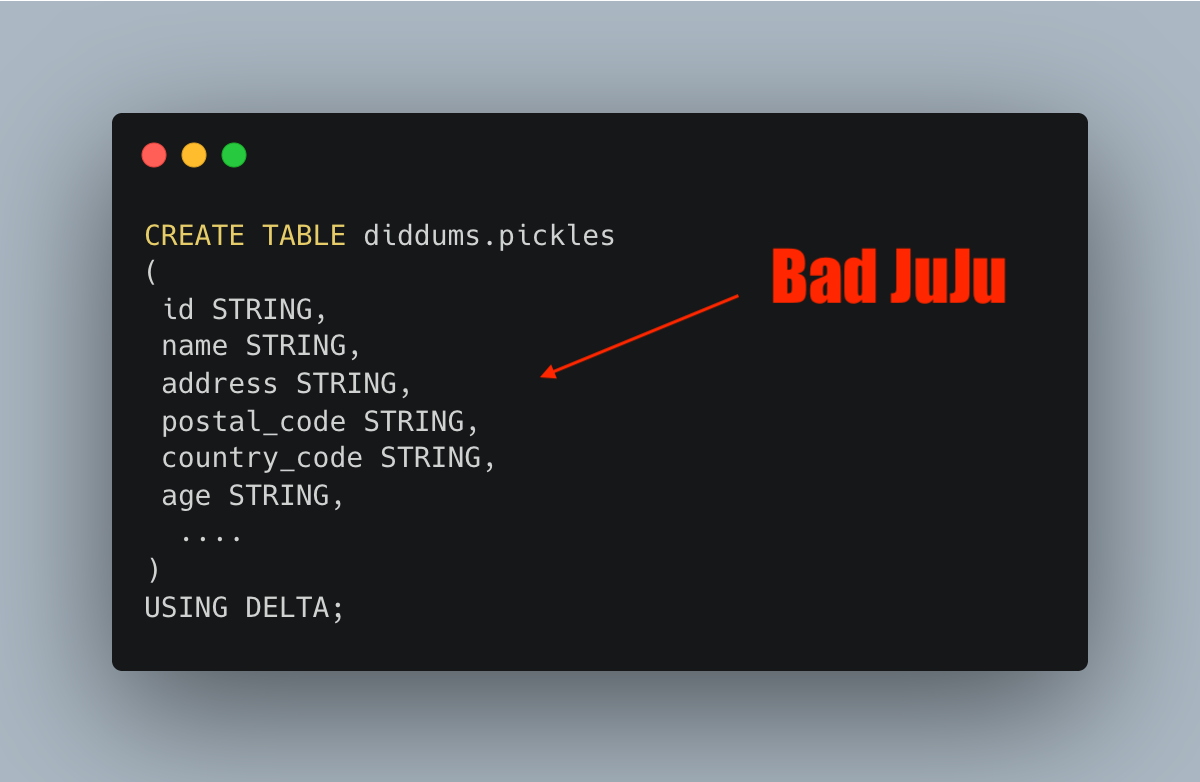

Heck, your Junior Engineer can even figure that one out if you show ‘em. It seems painfully obvious, yet it is ignored for the sake of speed, laziness, or “flexibility.” This will bite you more than anything else.
(I know technically most people consider NULL or not a constraint, but it’s usually written as part of the DDL).
So, you’re telling me you're willing to shell out serious and time to put some SaaS Data Quality platform in place, but you’re not willing to decide which columns should be STRING vs INT, and what can be NULL vs NOT NULL?
I will come out of this screen and slap you in the face.
Constraint
After schema comes the much-maligned but probably the most useful free data quality check, no SaaS required. Nothing to install, no fancy UI, no alerts. Just constraints.
Again, I’m about to blow your DQ mind.
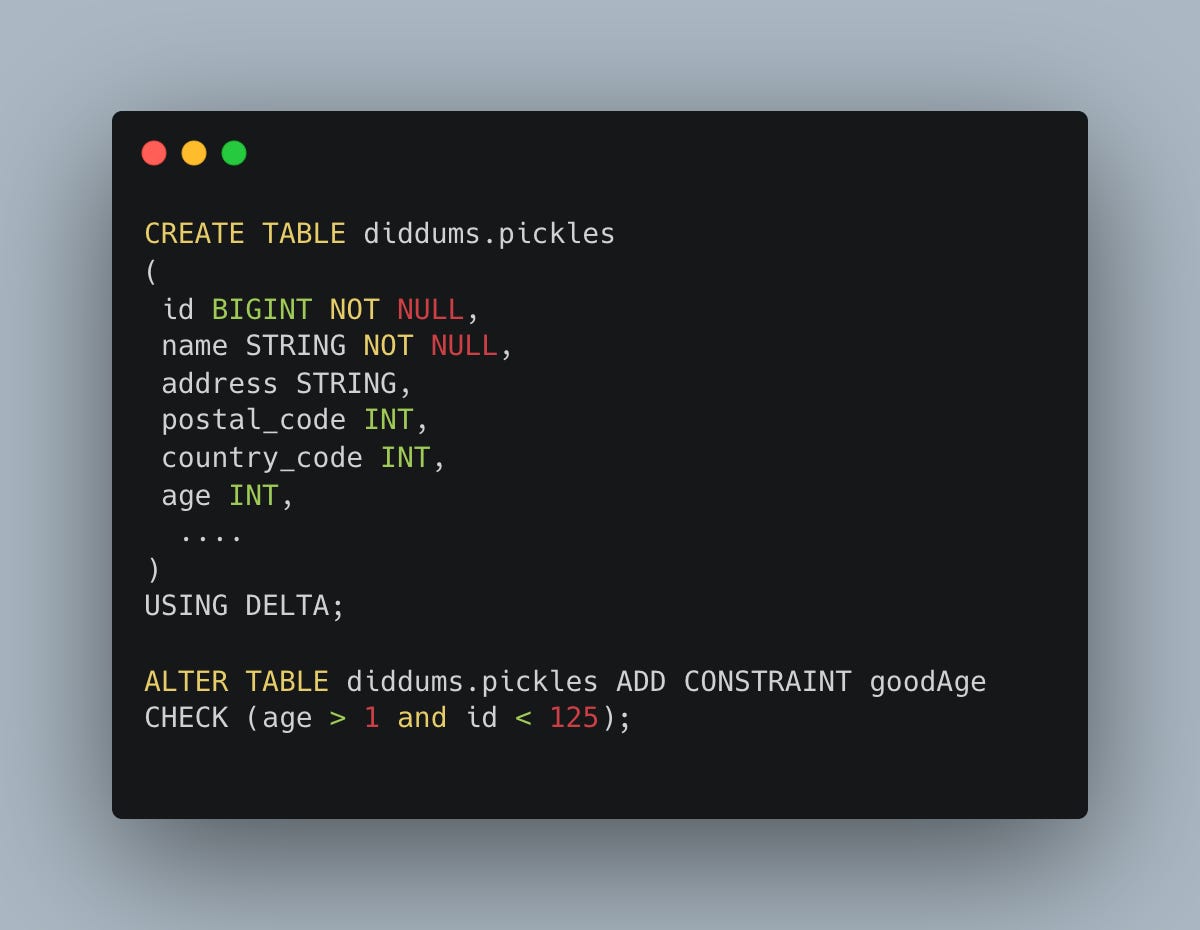
Wow, look at that, the exact same check as is probably written in about as many fancy DQ tools as you can imagine. Except here, we enforce Data Quality the minute it hits the Lake House. Imagine that.
The problem is that neither the schema nor the constraints for Data Quality are sexy. No one makes any money on this approach.
Testing (unit)
I bet you were not expecting this one, were you? Think about it for a minute. Many Data Quality checks are not only logical (e.g., someone cannot be less than 0 years old), but also business-specific.
This is sorta esoteric, but your Data Quality will never be any good if you don’t test your codebase. Many so-called DQ issues are directly related to incorrect or unexpected business logic
For example, is the amount column all in the same currency?
This sort of business logic is hard to capture in a schema/constraint, but easy to test for.
At the end of the day, with any approach, you are trying to get ahead of the ball, to force some rigidity and expect something from your data up front, not just shovel the slop forward and use expensive SaaS to solve your problems later.
The problem is, when it happens later, you’ve already buggered the system and someone has to clean it up.
SaaS Data Quality
Well, this is the moment I’ve been dreading all along. It’s been a while since I’ve poked at the open-source and SaaS options for Data Quality frameworks. Now is my chance to see if anything new has entered the scene, or if it’s the same old.
I don’t know what else to do but simply dig around in the digital mud and see what’s popping.
I would like to break them into open source vs. SaaS, but that line has been so blurred; it’s hard. We will try.
Let me just list the options.
Spare me your insolent comments about which tool I forgot. In all my googling and researching, there hasn’t been much change, though a few new tools have popped up since last time. To be honest, this is a good sign, for years, nothing has moved in this category.
First, let’s try to bucket these for our own sanity. Don’t quote me on this, it’s my best shot.

Looks like we have a mix of open source only, SaaS only, and a few handfuls in the middle. If you want my honest opinion, you should always pick something in the middle group.
We can go around in circles all day about semi-open source, rugs getting pulled, etc, but usually a SaaS with some open source on the side is a good sign, and that quality will probably be top-notch.
Also, not all these tools are made to do the same thing.
some are full-fledged observability + DQ
some are DQ only
some are Python-specific
some are for Spark
Truth is, you don’t have as many options as you think for your specific use case. For example, if you are running Snowflake, most of these are useless.
Again, here is my quick take on tooling support for these DQ frameworks. Spare me the angry comments, I won’t read them.
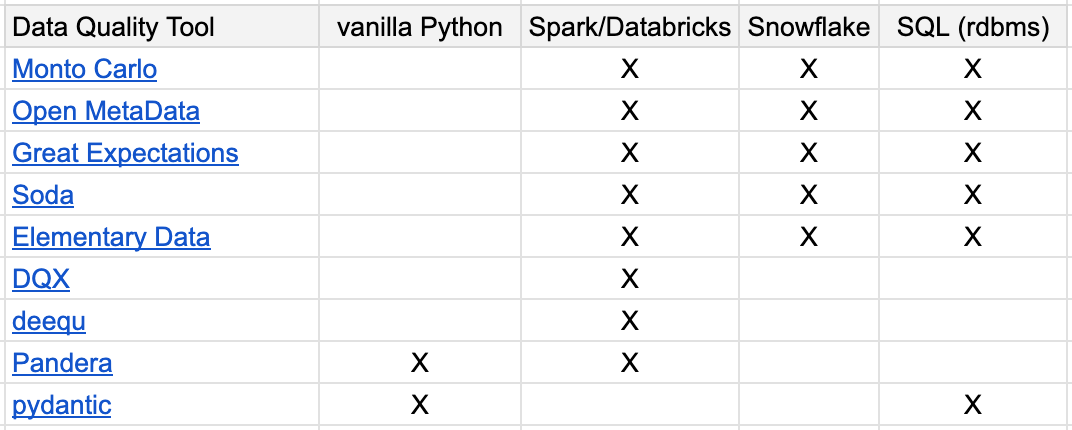
As you can see, even a cursory glance over the the array of DQ options will point out that the tool you use is most likely highly dependant on how that actual tool fits into your wider Data Platform framework.
These decisions are not made in a vacuum, you don’t simply pick one that looks cool and the force it onto your use case. It should be the opposite.
how complex you do you want your DQ to be?
what is your main datasource?
how large are the datasets needing DQ checks?
do you want to host the tool yourself?
These sorts of questions narrow down the focus and will mostly likely leave you two tools to choose from, maybe three.
Each Data Platform team has it’s own context in which they operate. Some perfer plug and play, others love drinking from the chalis of open-source.
Pick your poision.
I’m not going to spend anytime today going into the internals and “how to use” x, and y tool. If you’re interested in that sort of thing, let me know, drop a comment. I’m not opposed to it, I think generally implementation details in a post like this can simply be distracting and pulling you away from the high level decisions that are argubly more important.
Instead you should focus on …
Data Quality at home first.
schema
constraints
unit tests
Understanding your data very well
combined with your data types and DQ needs
Armed with these points well thought out and decided, the rest is simply up to you. Pick a tool that appears to fit well into your culture, data, and business needs.
Hi Daniel,
Thank you for the article. We have also seen that many organizations don't want to apply resources to fix data quality issues. DataKitchen provides a free and open-source tool, TestGen, that a motivated individual can use to influence the data suppliers. Check it out here: https://info.datakitchen.io/install-dataops-data-quality-testgen-today. The help page has a great introduction: https://docs.datakitchen.io/articles/#!dataops-testgen-help/introduction-to-dataops-testgen.
-- Gil Benghiat (Founder, VP) @ DataKitchen
The point about starting with schema and constraints before reaching for SaaS tools is so true. I've seen teams spend months evaluating DQ platforms when they still had everythng typed as STRING with nullable columns across the board. Once you nail down proper types and NOT NULL where it matters, you've already solved like 60% of your DQ headaches.