

Rust for the small things?
... but what about Python?


I’ve come to realize now that the demise of Python has been greatly exaggerated, in fact, it’s fake news … not going to happen. The rise of LLMs … with its attending scaffolding of Python has ensured that.
Things like Polars have cemented the idea of Rust-based data tools wrapped with Python is probably our future.
But, that doesn’t mean I don’t want to write in Rust for the everyday and mundane Data Engineering tasks. It does beg the question though … what would happen if we did?
Thanks to Delta for sponsoring this newsletter! I personally use Delta Lake on a daily basis, and I believe this technology represents the future of Data Engineering. Check out their website below.

Of course, there is a tradeoff with everything though …
Python requires less code
Does speed and safety matter in every application (probably not)
Developer efficiency matters
I suppose one could argue that every few milliseconds, or seconds, saved here or there … across an entire Data Platform … would add up to something real. Also, the idea that rusts strict compiler rules around the Borrow Checker, etc, would also add up to a more reliable and less breakable Data Platform.
All that being said, humans are humans and it ain’t going to happen.
Testing Rust in the small things.
So, today I want to test Rust in the small and mundane parts of Data Engineering in general. I was thinking we could start with doing some s3 operations … from the perspective of …
the lines of code written
the performance
So, without further ado, let’s get cooking. First, let’s simply count the number of files in a bucket and prefix location with Rust.
So here is my Rust code, I’m no expert so take it for what it is.
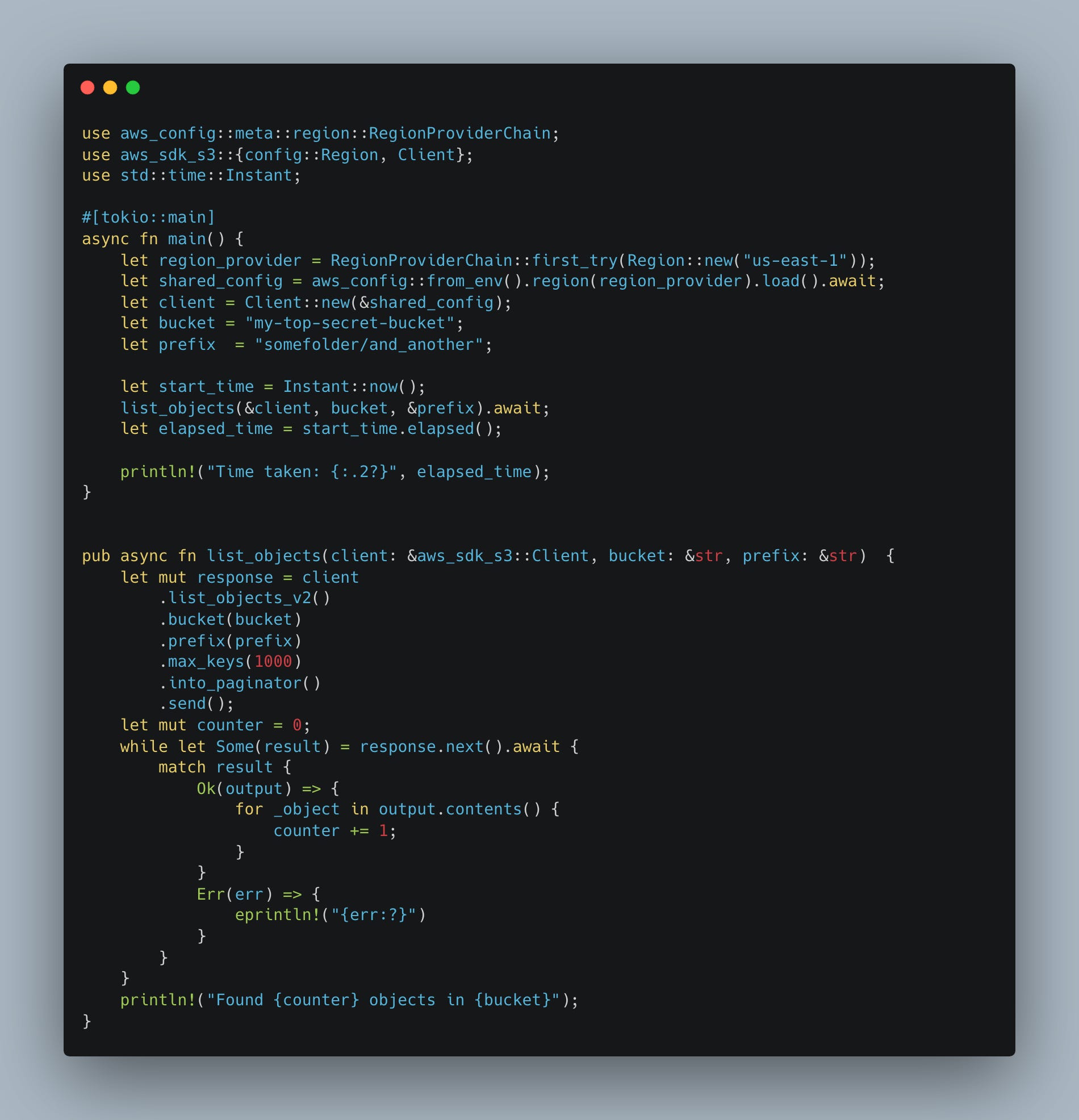
And the results
Found 250624 objects in my-top-secret-bucket
Time taken: 42.79sThere are roughly 43 lines of code. I find it’s not overly verbose or hard for even one of those lowly Python coders to follow what’s happening. In fact, when I had ChatGPT convert the Rust code to Python for me, it only went down to 31 lines of code.
I know people say Rust is too hard to write, or too much overhead, but it probably has more to do with the problem space itself.
More small things with Rust.
I tried to think of other smallerish but uniquely Data Engineering type tasks I’ve had to do in the past 10 years … and one popped to mind.
Sometimes we get strange flat files that have to be pre-processed before they get ingested into downstream systems, like Spark. I’ve run across this one before …
… a flat file that has a header and footer that need to be stripped out.
This one has come up more than once. You get CSV or TSV-type files, but they come with a maybe timestamp in the header and footer that needs to be stripped before you can actually load them. Very strange, but surprisingly common for files being pumped out of legacy systems.
I just took one of the Divvy Bike trip free datafiles (CSV) and modified it to have this junk header and footer row(s).


So we need some Rust code that would maybe be running inside a Lambda or triggered elsewhere that would take these incoming files, strip out the first and last record of every file (the junk) … and pump out a clean CSV.

Pretty fast.
File processed successfully.
Time taken: 410.71msSeems to have worked well.

I do have to admit, if you’re a Python person used to working with files then this Rust might start to get a little weird, mostly because Rust’s verboseness starts to show its ugly head.
We had to create a File …
let temp_file = OpenOptions::new()
.write(true)
.create(true)
.truncate(true)
.open(&temp_file_path)?;as well as a Writer
let mut writer = BufWriter::new(temp_file);Not only that but the logic I used is a little strange.
let mut lines = reader.lines().skip(1);
let mut prev_line: Option<String> = None;
while let Some(Ok(line)) = lines.next() {
if let Some(prev) = prev_line.take() {
writeln!(writer, "{}", prev)?;
}
prev_line = Some(line);
}We skipped the header line out of the box with skip(1) … easy enough. But we needed a way to skip the last line. ( I guess we could have just counted the number of lines upfront )
In my above approach, everything seems a little awkward, it makes you stare for a minute or two, to catch on.
Python check-in.
We should probably check in with Python at this point, so no one gets their feelings hurt. What would this last little tidbit in Rust that started to get complicated and verbose look like in Python?
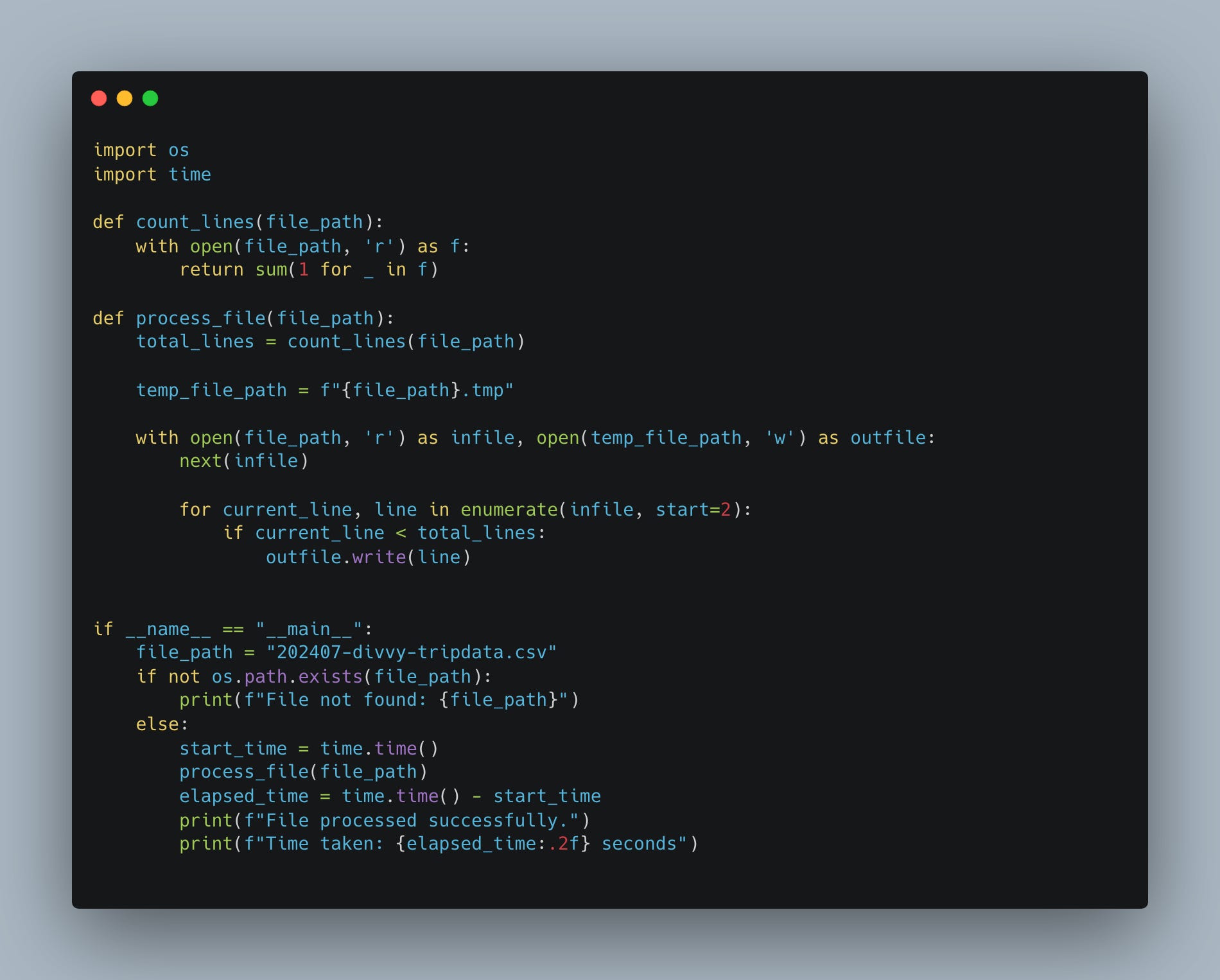
Now don’t yell at me about the Python either, we are here for fun, not for work. What I want to notice now is how few lines it takes in Python.
File processed successfully.
Time taken: 0.74 seconds (740 ms)Whereas our first easy Rust script didn’t differ much from the Python version (we asked ChatGPT to convert it), this second little guy … when the requirements start to get complex, the Rust is roughly double the code size.
Now I’m not saying one is better than the other, that’s up to the engineer in my opinion.
if you need bulletproof and fast, Rust is always the answer.
if you want easy and simple, Python is always the answer.
The Reality
The truth of the matter is that Rust probably will never be used for the small stuff in Data Engineering. Even though I wish it would. I think Rust is fun and it’s a hard teacher that makes us all better programmers, especially those of use that use Python on a daily basis.
Even if you're seasoned in Rust, it's hard to ignore the ease of writing Python and its more mature ecosystem of third-party functionality. That said, as a rustacean, I'd lose time trying to figure out how to do something in Python that I could have just knocked out in Rust, so YMMV.