

Delta Lake + DuckDB. Catalog Commits with Unity Catalog. Unlocking Concurrent Ingestion.
why isn't anyone talking about this?


Ok, sometimes I honestly get amazed at what squeaky wheel gets the grease and what doesn’t in the data community at large. *Sigh. Well, I sort of get it, but as someone who loves the Single Node Rebellion, it’s hard not to call my mom about this.
The world, and I, have embraced the Lake House as the data platform architecture of choice (yes, it is an architecture), Delta Lake and Iceberg becoming one, we have all drunk of the chalice and are reluctant to put it down.
Part of the problem, if you can even call it that, is that we (the collective we) have, as a side effect, become addicted to clusters and high-cost compute. Sure, Databricks Serverless has come along, and is indeed welcome; tools like DuckDB, Polars, and Daft have for some time supported Unity Catalog access to the Lake House.
But we don’t turn a blind eye to the complexity and issues this might create.
In the past years, I’ve been the dude pushing DuckDB to prod inside Lambdas and letting ‘er rip on Unity Catalog Delta Lake tables. But ya gotta be careful when you're trying to touch the sun. At the most basic level, Delta Lake and like Lake House storage layers are all about transactions, and once that word appears, it’s easy to blow stuff up.
How do you ensure you’re working on the right table version? How do you allow multiple writers, say DuckDB, to hit the same table and not FUBAR your production tables?
That’s what we are going to talk about today.

Le Problème (the problem)
I sorta mentioned the current “problem” with the Lake House architectures for the last few years. They have mostly been one-trick ponies, wonderful in their inception and in delivering data at scale, but poor at adopting real-world multi-tool read/write support.
Sure, we’ve had read access for a few years now for a variety of tools, but that only gets a guy so far. The ever reached for golden star that unlocks the potential for bespoke, handcrafted, multi-engine unlimited access and interaction has been mostly a untouched relic used by delta-rs and dynamodb mythical creatures.
Only a chosen few have the courage to walk down that path less traveled.
So, for the masses, we’ve had to stick to our Spark Clusters, Serverless, Databricks Connect, or whatever … to get the true read, and more importantly, write semantics, needed to build most production pipelines.
Sure, we’ve had DuckDB and Polars integrations into Unity Catalog for the brave, but you were still playing with fire and banging rocks together.

What were we missing?
Simplistic concurrent writes via common data tooling.
Simple is good, doesn’t have to be fancy, to open up the Lake House architecture to be more …
flexible
multi-engine
full production-like support for all operations
Is that so much to ask for?
Then the Lord said … “Let them bring forth Catalog Commits.”
Let’s get to the matter at hand. Also, just because I’m singing the praises of Unity Catalog and Catalog Commits here, I will make some critical comments at some point. Ya’ know I bring the heat at all times and in all seasons.

I’m not going to give a ton of background here, just the basics, so everyone is on the same page about why Catalog Commits are a big deal. At the core of the problem, Delta Lake provides ACID capabilities on top of object storage. This makes the implementation simple, and the need for a Data Catalog simplifies the architecture.
But also surfaces issues. Databricks sums them up well.
“… external engines writing to Delta tables directly in object storage cause catalog metadata, like schemas, to silently diverge from the actual table state.”
“… every engine, tool, and agent can access tables differently, resulting in fragmented table discovery, inconsistent auditing, and no standardized enforcement of row or column-level controls across systems.”
“… open lakehouse architectures historically have not supported atomic writes spanning multiple tables.”
The only real option to solve these issues was/is for Delta Lake to follow in Iceberg’s footsteps, for once, and move towards making a Data Catalog the primary means by which someone or something interacts with the Lake House.

Again, why is this a big deal? Well, because “we” have a whole new conceptual data-processing and pipeline architecture available now … for pretty much any and all Lake House ingestion and processing.
Something we didn’t really have, or didn’t have much of before.
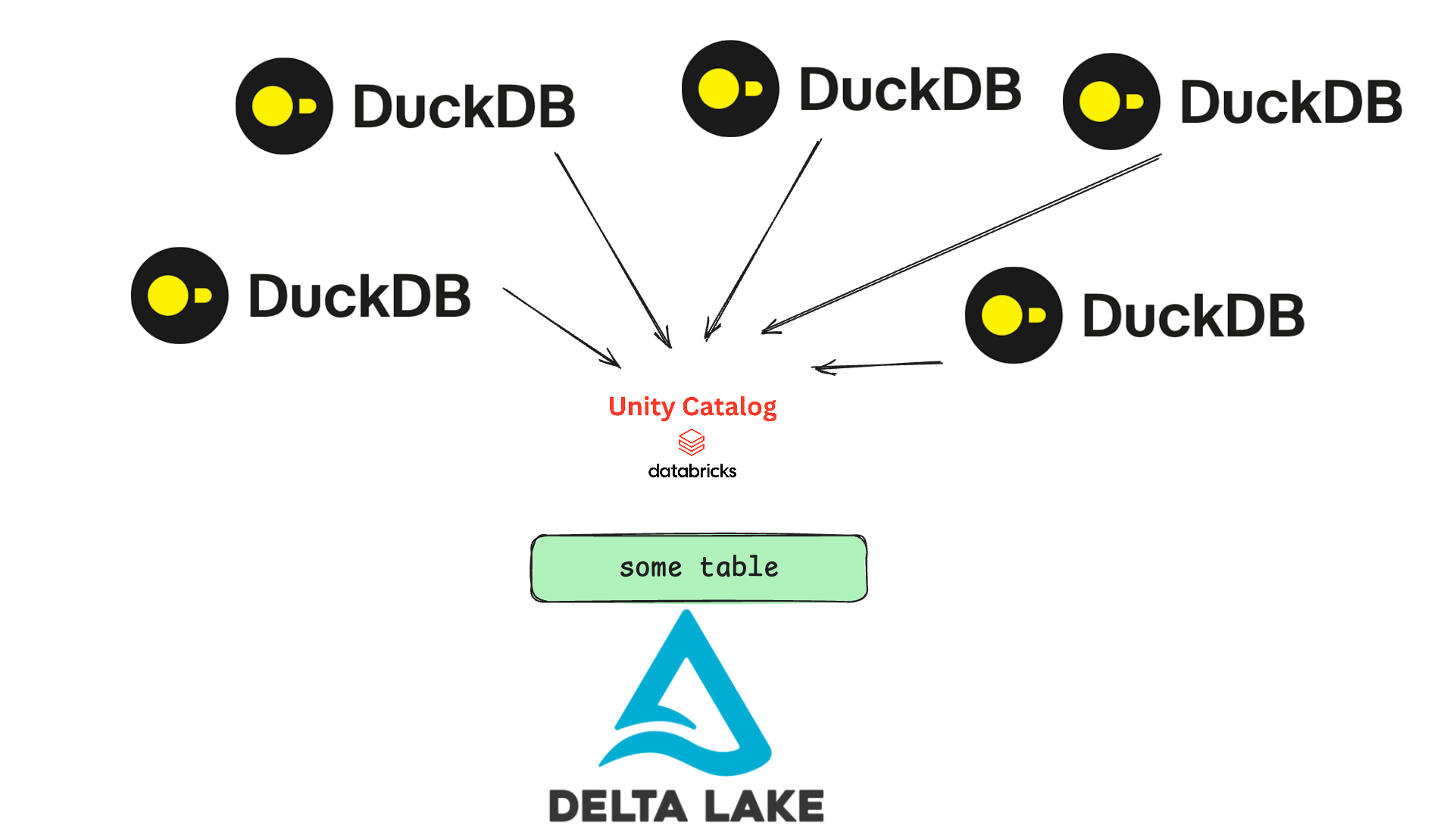
I think I’ve been pontificating enough at this point, and I would like to simply show you, on my personal AWS and Databricks accounts, how we can think about changing the data processing paradigm in the Lake House now.
Simplicity, don’t forget that part. What I’m most excited about is the simplicity of this architecture.
Using DuckDB + AWS Lambdas + Databricks Delta Lake
Ok, so there is most likely no more basic and common data ingestion pattern on a Databricks Lake House platform than the simple ingestion of CSV files into some Medallion Architecture.
Typically, this would be done with a Databricks Job, using Spark. Not a big deal, except for your compute bill at the end of the month, AND the simple fact that even processing a few hundred CSVs every day is simply a little Spark overkill. You don’t exactly need distributed compute to do that.
So, what if we could just have some AWS Lambdas with triggers watching some S3 bucket(s) where the CSV files land, and let DuckDB inside the Lambdas write that data ingestion into the Lake House concurrently and at scale, without any worries?
Talk about simple. And fun.
First, we need a Catalog Managed Delta Table.
So, I’ve already got some Delta Lake tables banging around in my Databricks account. We will use the old and trusty Divvy Bike trips table and use some of those open-source datasets/CSVs for our little project.
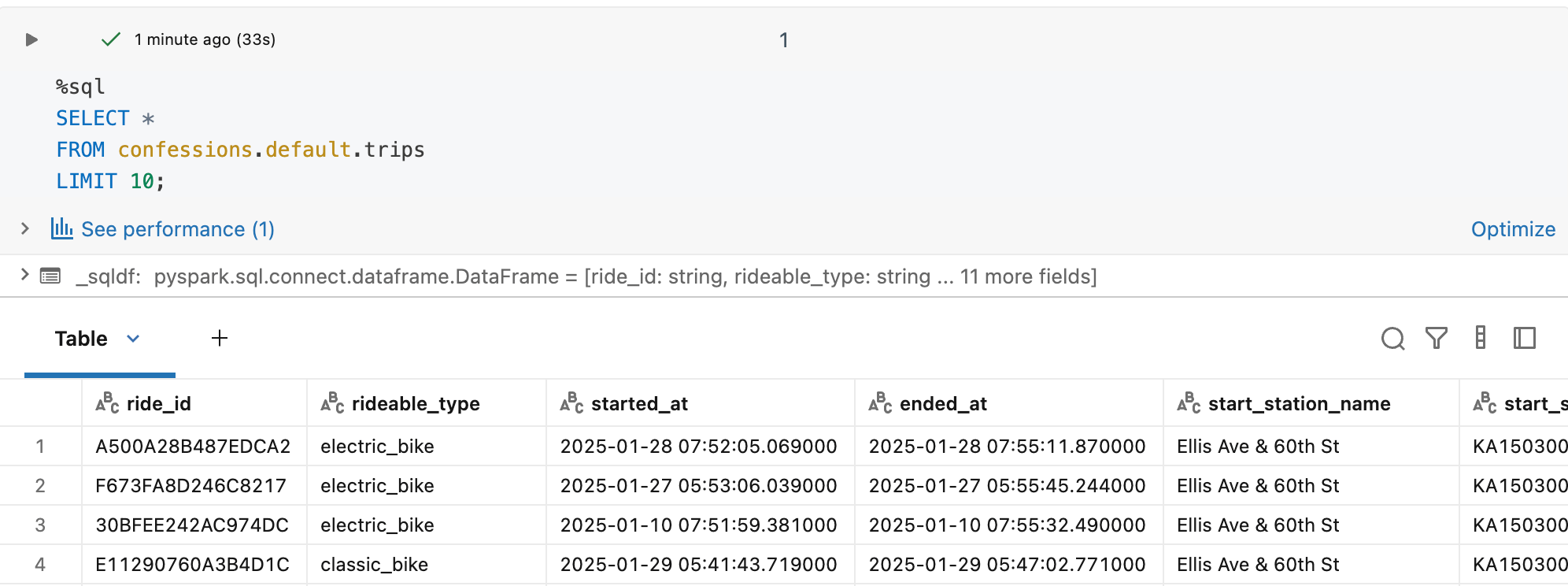
First, let’s run a command to upgrade our nasty old Delta Lake so it can handle new-fangled stuff.

Next, we need two things related to our Catalog: either OSS Unity or Databricks Unity.
Workspace URL
PAT token
This is how our DuckDB, or whatever engine for you, will hit our Lake House from inside an AWS Lambda.
DATABRICKS_HOST = os.environ["DATABRICKS_HOST"]
DATABRICKS_TOKEN = os.environ["DATABRICKS_TOKEN"]Also, let’s use a Dockerfile we can build and an ECR with AWS for running the Lambda.
FROM --platform=linux/amd64 public.ecr.aws/lambda/python:3.12
RUN pip install --no-cache-dir uv && \
uv pip install --system --no-cache "duckdb"
RUN mkdir -p /opt/duckdb_extensions && \
python -c "import duckdb; c=duckdb.connect(config={'extension_directory':'/opt/duckdb_extensions'}); c.execute('INSTALL unity_catalog'); c.execute('INSTALL httpfs'); c.execute('INSTALL aws'); c.close()"
ARG DATABRICKS_HOST
ARG DATABRICKS_TOKEN
ENV DATABRICKS_HOST=${DATABRICKS_HOST}
ENV DATABRICKS_TOKEN=${DATABRICKS_TOKEN}
ENV DUCKDB_EXT_DIR=/opt/duckdb_extensions
COPY main.py ${LAMBDA_TASK_ROOT}
CMD ["main.lambda_handler"]Nothing much there, simple and simple. The lambda code itself is as uncomplicated as they come. These are the sort of things we should all default to.
