

Lord have mercy. Apache XTable.
... add another one to the list


I feel like we’ve seen this story before, haven’t we? I swear we’ve been over this a few times now. Yet here we are again, doomed to live in the eternal cycle of the newest “god table format” on the scene.
It’s like the Data World is on the quest for the One Ring of Power, except we are unsure who Gandalf and Saruman are. So here we are, the Lake House Table Format War rages on in earnest with new soldiers being called on to fight the good fight and take up arms.
Either way, here we are, and I’ve been hearing rumors that Apache XTable is the long-awaited one-table to rule them all. We shall see.
I’m not sure how long or short this will be; I know nothing about XTable, so it will be a journey of surprises for us all. Let’s do what we do and kick the tires.

What is Apache XTable, and why do we need it?
Apache XTable™ provides cross-table omni-directional interop between lakehouse table formats
Apache XTable™ is NOT a new or separate format, Apache XTable™ provides abstractions and tools for the translation of lakehouse table format metadata"
- XTable
Well, this is interesting. Honestly, knowing nothing about it, I pretty much assumed that Apache XTable was yet another format for our Lake Houses.
However, the documentation/website specifically states that it is NOT another table format but an “omnidirectional interop” between formats.
Well, now I am interested.
They XTable websitehttps://xtable.apache.org/ has a nice diagram that give us an conceptual overview of what the idea is.

I personally have not found the need (working on a small team) to have multiple copies/versions/whatever of my Lake House tables in different formats. But, based on a lot of the comments I’ve seen online, this appears to be more and more common.
I can’t claim to understand all the reasons for this, but I suppose in large organizations of size when many thousands of datasets, this sort of inter’opting of formats could indeed be handy.
Apache XTable simplifies this process by reading your table’s existing metadata and generating compatible metadata for other table formats.
Instead of rewriting or duplicating data, XTable™ leverages each table format’s native APIs to make your existing data instantly readable as if it were originally written in Delta, Hudi, or Iceberg. The converted metadata is stored in the respective format’s default location:
Delta Lake →
_delta_log/Apache Iceberg →
metadata/Apache Hudi →
.hoodie/
This means you can query the same data using different engines without complex migrations. For example, in Apache Spark, you can seamlessly read your data using:
spark.read.format("delta | hudi | iceberg").load("path/to/data")Backup a second.
Before we get ahead of ourselves, I think what we greatly feared is true, based on the example above of Apache Spark. If you have any stars in your eyes we can quickly expel them by heading over to the GitHub page for XTable and reading about “installing” and “using” it.
it requires Java (hence using Spark in most cases probably)
the example shows a large YAML file to setup different formats
you have to run a JAR command to do the work.
Here is an example YAML configuration.
sourceFormat: DELTA
targetFormats:
- HUDI
- ICEBERG
datasets:
-
tableBasePath: s3://confessions-of-a-data-guy/hobbits
tableDataPath: s3://confessions-of-a-data-guy/hudi/hobbits/
tableName: hobbits
namespace: my.dbAnd the Java command.
java -jar xtable-utilities/target/xtable-utilities_2.12-0.2.0-SNAPSHOT-bundled.jar --datasetConfig my_config.yaml [--hadoopConfig hdfs-site.xml] [--convertersConfig converters.yaml] [--icebergCatalogConfig catalog.yaml]Well … this is an “incubating” Apache Project so we can’t pull out the pitchforks and torches and go for em’, even if want to. I’m trying not to ole’ Gandalf Stormcrow, but most of hate doing Java crud.
Can we make it work on Databricks?
Anywho, I think the best thing to do here is try to see if we can make this work inside a Databricks environment. Sure, we could do the whole Docker thing, but honestly, that simply is just playing around a laptop.
I would prefer to see if we can make this work out in the wild, I think it will gives us more of a a sense of at what stage of life we find XTable.
So here is what I propose …
clone XTable git repo
build the JAR
put JAR into Databricks DBFS
Point JAR / command line at existing Delta Lake (Unity Catalog table in S3) … ask for Iceberg and Hudi versions.
Try to read the XTable Iceberg and Hudi tables with Spark.
Decide if this thing is what it says it is. Here goes nothing.
git clone git@github.com:apache/incubator-xtable.git
cd incubator-xtable
## if you're running God's OS run something like this if you need Maven
export HOMEBREW_NO_AUTO_UPDATE=1
brew install maven
##
mvn install -DskipTestsI came upon the fist error, which is no surprise because I didn’t listen to what they were telling me … build on Java 11 or use the Docker image.
Downloaded from central: https://repo.maven.apache.org/maven2/com/squareup/okhttp3/okhttp/4.12.0/okhttp-4.12.0.jar (790 kB at 1.4 MB/s)
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for XTable Project Parent POM 0.2.0-SNAPSHOT:
[INFO]
[INFO] XTable Project Parent POM .......................... FAILURE [ 16.886 s]
[INFO] XTable Project API ................................. SKIPPED
[INFO] XTable Project Hudi Support Parent POM ............. SKIPPED
[INFO] XTable Project Hudi Support Utils .................. SKIPPED
[INFO] XTable Project Core ................................ SKIPPED
[INFO] XTable Project Hudi Support Extensions ............. SKIPPED
[INFO] XTable AWS ......................................... SKIPPED
[INFO] XTable HMS ......................................... SKIPPED
[INFO] XTable Project Utilities ........................... SKIPPED
[INFO] ------------------------------------------------------------------------
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 17.622 s
[INFO] Finished at: 2025-02-16T14:20:29-06:00
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal com.diffplug.spotless:spotless-maven-plugin:2.43.0:check (default) on project xtable: Execution default of goal com.diffplug.spotless:spotless-maven-plugin:2.43.0:check failed: You are running Spotless on JVM 23. This requires google-java-format of at least 1.17.0 (you are using 1.8).Let’s save time and switch over the building the JAR with the provided Dockerfile.
docker build . -t xtableWell, that gave us another error.
danielbeach@Daniels-MacBook-Pro incubator-xtable % docker build . -t xtable
[+] Building 0.1s (1/1) FINISHED docker:desktop-linux
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 2.37kB 0.0s
=> WARN: FromAsCasing: 'as' and 'FROM' keywords' casing do not match (line 19) 0.0s
1 warning found (use docker --debug to expand):
- FromAsCasing: 'as' and 'FROM' keywords' casing do not match (line 19)
Dockerfile:49
--------------------
48 | ENTRYPOINT [
49 | >>> "java", \
50 | >>> "--add-opens=java.base/sun.nio.hb=ALL-UNNAMED", \
51 | >>> "--add-opens=java.base/sun.nio.ch=ALL-UNNAMED", \
52 | >>> "--add-opens=java.base/java.nio=ALL-UNNAMED", \
53 | >>> "--add-opens=java.base/java.lang.invoke=ALL-UNNAMED", \
54 | >>> "--add-opens=java.base/java.util=ALL-UNNAMED", \
55 | >>> "--add-opens=java.base/java.lang=ALL-UNNAMED", \
56 | >>> "-jar", \
57 | >>> "./app.jar" \
58 | >>> ]
59 |
--------------------
ERROR: failed to solve: dockerfile parse error on line 49: unknown instruction: "java",
View build details: docker-desktop://dashboard/build/desktop-linux/desktop-linux/g8na5c2io68ocgfikmuw7hr4xI am getting somewhat annoyed at this point, although not surprising for a Java project. I’m thinking to try to get myself to the end point (having a XTable built JAR as quickly as possible), I will just make my own Dockerfile that actually works.
FROM ubuntu:24.04
ENV TZ=America/Chicago
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
RUN apt-get update && \
apt-get install -y --no-install-recommends openjdk-11-jre-headless wget vim software-properties-common maven git-alldocker run -it -v "$(pwd):/app" xtable /bin/bash
>> git clone https://github.com/apache/incubator-xtable.git
>> cd incubator-xtable
>> mvn clean package -DskipTestsNow why Apache XTable couldn’t provide us with a working Dockerfile is beyond me. Looks like our little Dockerfile that could worked.
[INFO] Reactor Summary for XTable Project Parent POM 0.2.0-SNAPSHOT:
[INFO]
[INFO] XTable Project Parent POM .......................... SUCCESS [ 19.439 s]
.....
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 06:48 min
[INFO] Finished at: 2025-02-16T15:35:58-06:00
[INFO] -----------------------------------------------------------------Now at this point we should have the JAR we need to run commands that will create our “interopt” tables for Delta, Hudi, and Iceberg.
I was initially thinking we should do this all inside Databricks, but now that I understand more of what is going on here, that probably isn’t really necessary.
if we really wanted to do this in a Production environment we would probably …
write a script to automate this task over many tables
as long as we have creds for whatever environment (aws, etc)
I still want to see if this Apache XTable command will work on top of an EXISTING Delta Lake (Unity Catalog) table and make us a Hudi and Iceberg version.
Brass Tacks.
First thing to do is go find us a Unity Catalog Delta Table and then make us a YAML config file to match. Luckily I have a few spare tables rattling around my personal Databricks account, this should work fine.
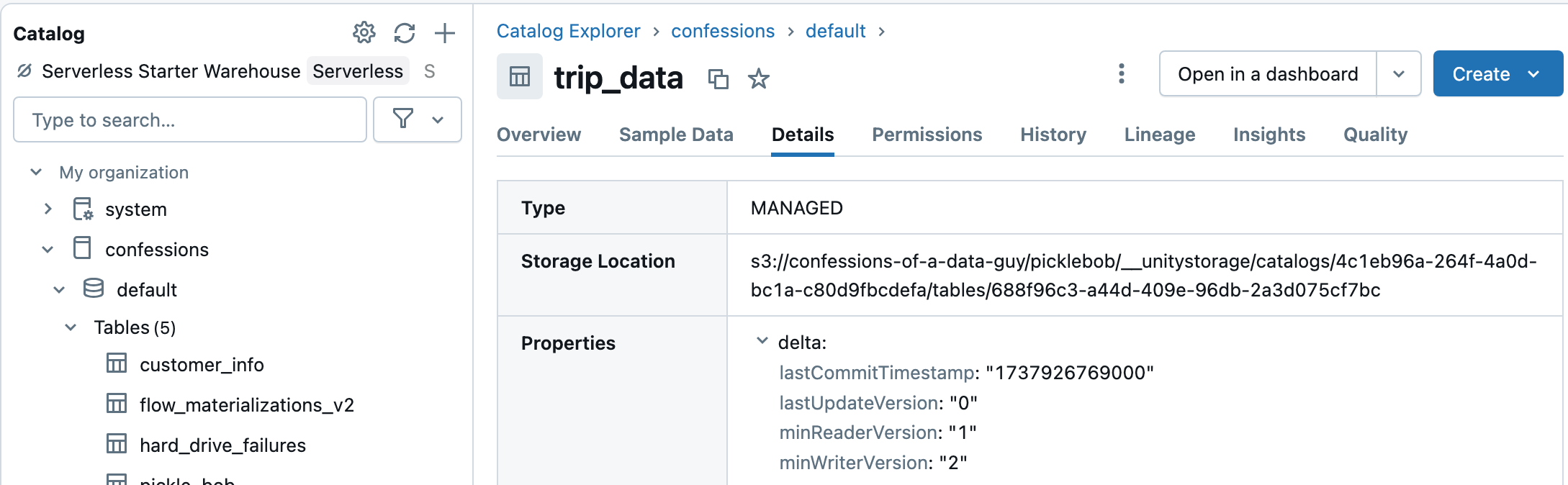
What I need is to grab the s3 URI of the table and use it for our config file we will run the XTable command with.
sourceFormat: DELTA
targetFormats:
- HUDI
- ICEBERG
datasets:
-
tableBasePath: s3://confessions-of-a-data-guy/picklebob/__unitystorage/catalogs/4c1eb96a-264f-4a0d-bc1a-c80d9fbcdefa/tables/688f96c3-a44d-409e-96db-2a3d075cf7bc
tableName: trip_dataWhat is also not clear to me at this point is where XTable will store these Hudi and Iceberg “tables.” I could not sus out in the documentation or configs of the YAML if you can specify them or not. Does it just create them in the same location?
I’m nervous. Saved the above as config.yaml. What do you think is going to happen?? (run this in the same place you built and ran the maven command)
java -jar xtable-utilities/target/xtable-utilities_2.12-0.2.0-SNAPSHOT-bundled.jar --datasetConfig config.yamlMy command line started to crazy, which is a good thing probably, means it’s doing something. (If you look closely you can see it talking about Hudi for example and referencing our s3 Table.)

All done.
2025-02-16 15:56:33 INFO org.apache.xtable.conversion.ConversionController:213 - Sync is successful for the following formats HUDI,ICEBERGI was unable to find where this thing spit out where my new XTable (Hudi and Iceberg) formats, and it didn't tell me where they could be read from. I guess we should go dig around that Delta Table s3 spot? (annoying … am I supposed to guess??)
Here is the S3 location on AWS for that Delta Table. I’m sorta assuming some of the NON _delta_log stuff is what we just created?
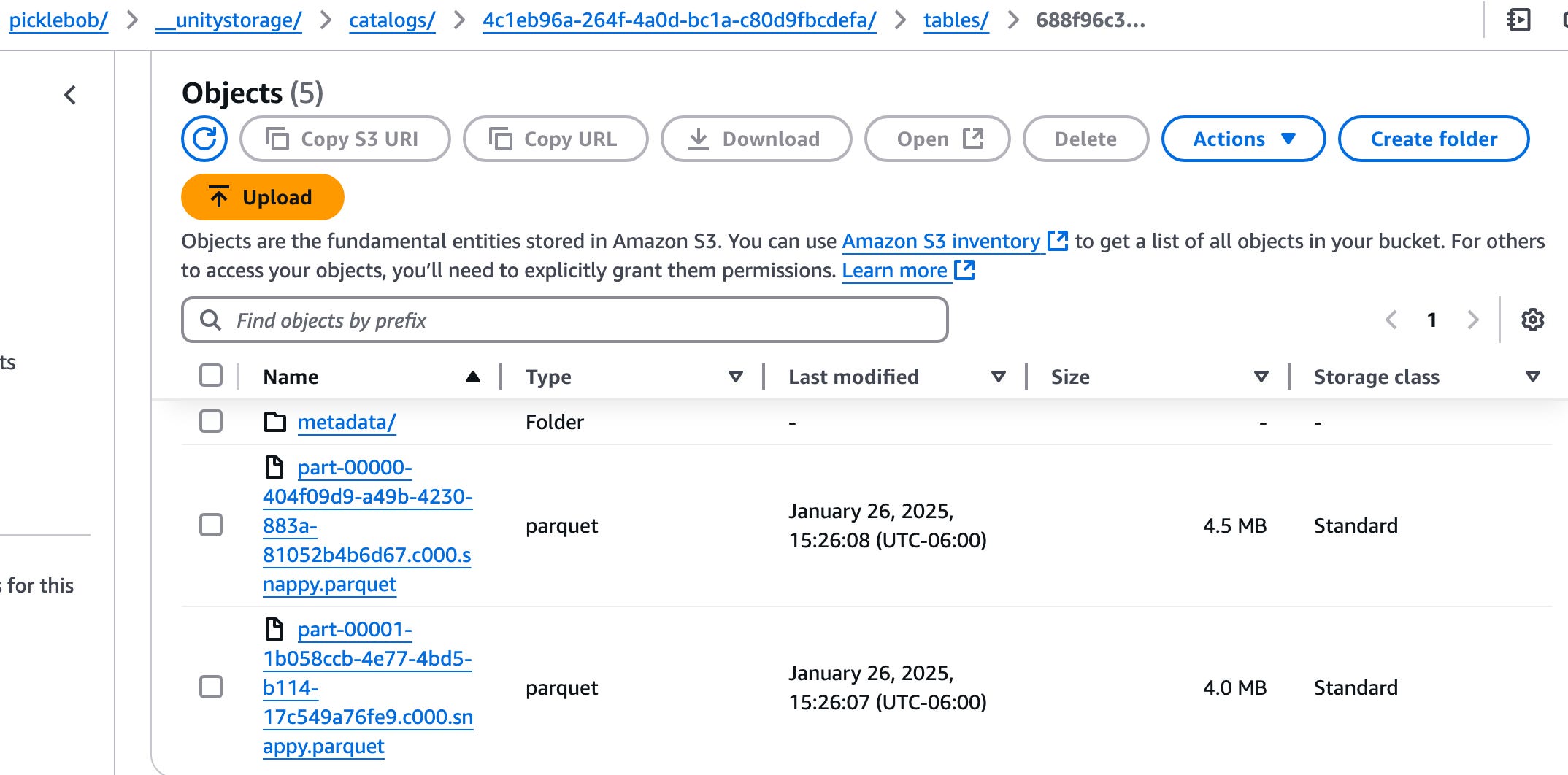
I confirmed this by opening the “.hoodie/” location and seeing the created timestamps were current. So … can I go into my Databricks account and read this Delta Lake Unity Catalog table as a Hudi?
it appears the metadata folder is the Iceberg table
the .hoodie folder is the Hudi stuff
So, let’s try to display this table … with NOT Spark … but something else … like Daft. This will ensure that XTable is creating legit tables.
Here is our base Delta Lake table.

Can we read it as Hudi now? No?? Just returns an empty Dataframe, not even and error thrown. Strange eh?

How about Spark with Hudi?
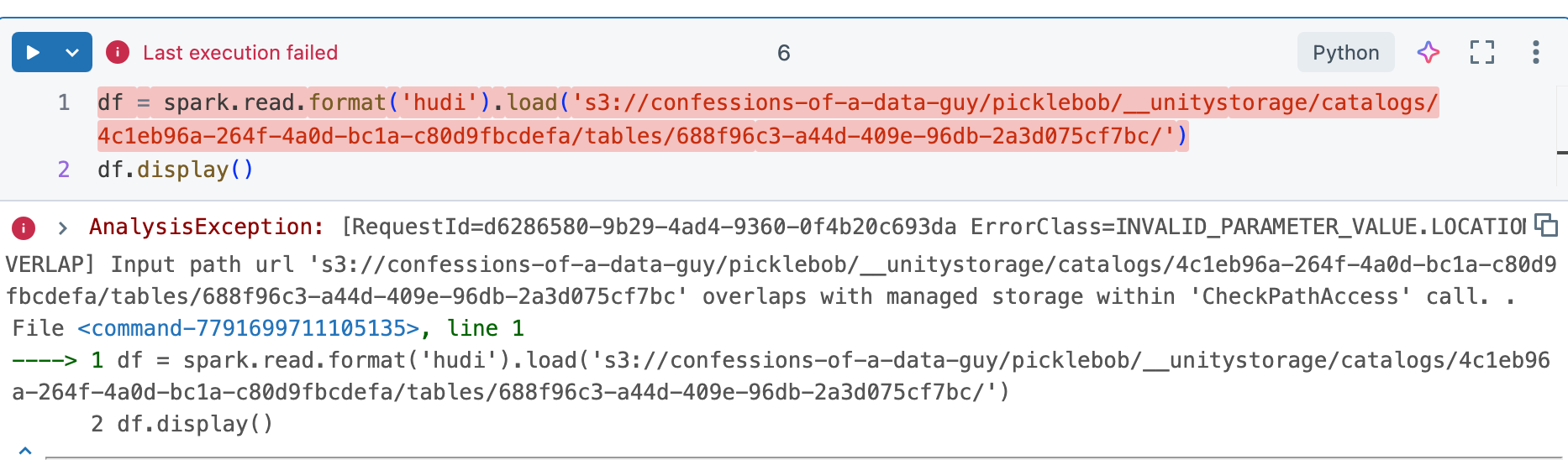
No such luck, screaming about paths and overlapping crap. (I tried with Iceberg got same errors).
Didn’t matter if I read the base path (like the docs show) or the actual folders it created etc, always the same Spark error.
Try and try again.
Not sure if this has something to do with these Unity Catalog tables messing with things? I want to at least do my best to make this work, so how about let’s create a new NON-managed and NON-Unity Delta Table and try this all again?
It’s not like I have anything better to do on a Sunday. Here is our fresh start.
trips = spark.read.csv('s3://confessions-of-a-data-guy/trips/202412-divvy-tripdata.csv', header=True)
trips.write.format('delta').save('s3://confessions-of-a-data-guy/buggerall')I went ahead and updated that XTable config YAML file and re-ran the command on this new raw and unmanaged Delta Table. It did it’s thing again writing out the same directories in S3 as before.
Note the two new table locations, metadata and .hoodie (Iceberg, Hudi)

So, let’s try it again, read Hudi with Daft. No luck, same error.

Ok, what about using Spark with the Iceberg version? I’m desperate to get some part of XTable working here.
This was a bomb as well, it appeared Spark was picking up the Delta log in the same spot and yelling when trying to read it as Iceberg. So much for seamless uh?
At this point I have no idea of this is a Databricks thing or not. (I’ve used UniForm tables with no problems on Databricks)

What if we point Spark right at the Iceberg “meta” folder we know exists in that location? No juice. Bloody buggers. Could it be Databricks environment somehow messing with this all?
I decided to switch back to just a local environment and see if locally I could use Polars or something to read the Iceberg table.
import polars as pl
storage_options = {
"s3.region": "us-east-1",
"s3.access-key-id": "XXXXXXXXXXXXXXXX",
"s3.secret-access-key": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
}
df = pl.scan_iceberg('s3://confessions-of-a-data-guy/buggerall/metadata/v2.metadata.json', storage_options=storage_options)
print(df.collect())Well finally.

I did have to directly give it the location of the Iceberg meta.json file, otherwise it was still throwing errors.
in the docs they make it appears if you put in the base table location it will work, it does not, from my experience.
Ugg … I’m done for now. That IS what you would call incubating. To be honest I didn’t share even half the errors and crud I had to go through even to get to this point.
I probably won’t be returning to Apache XTable anytime soon, not until it gets a little more stable and has some more time under it’s belt and improvements made.
An important question.
When reading the documentation for XTable and important question came up. It provides both “incremental” and “full” sync modes between the table formats.
Does this mean to keep say a Delta Lake table in sync with Hudi and Iceberg we would have to run this on a daily+ basis? This is unclear to me.

Signing Off.
Well, that does it for kicking the tires on XTable. My foot hurts. I guess I can see the reason why they made this, although Databricks UniForm seems light years ahead to me (worked out the box).
Trying not to be too hard on an incubating project, probably lots of work to come I would think.
Hey Daniel! I am one of the devs that work on Apache XTable and just wanted to say thanks for covering our project in your blog. We do appreciate feedback as we are an early stage project and want to help the data community with their pain points. If you want to create any github issue https://github.com/apache/incubator-xtable/issues for issues you ran into or things you would like to see in the future we can try to take it up at some point!
I truly look forward to when your push notification pops up on my phone so I can read about whatever 1) cool tool has come out or 2) some fantasy project some company has released that has no business being GA