

The Single Node Rebellion
a tale of revolt


The real question is, do you think Spark is the bloody British, the AWS EC2 instance is Boston, and DuckDB + Polars are the John Adams and George Washington, bent on freedom or death? You paid attention in history class, didn’t you?
I can see it.
The natural evolution of things, the rise and fall of nations, and the evolution of technologies. You will never get me to say that Spark is going anywhere, anytime soon. It’s not.
The Lake House, built on storage formats like Delta Lake and Iceberg, is the new Oracle and SQL Server; decades will pass before Spark and Lake House are gone.
But all rebellions start at the zenith of the great powers; overlooked users with less than a TB or two of data get upset with their cloud bills. A tale as old as time.
Big, or not so big.
It’s something everyone knows but no one talks about. There are actually not very many organizations that have and work on “Big Data.” Read the DuckDB summary of the Redshift files, an interesting look into the size of datasets, and better yet, the size of data queried in individual pipelines.

The truth is, “Big Data” is in the eye of the beholder. We all think our data is big when, indeed, it is not. Yes, there is Big Data floating around out there, and some big queries need to crunch years’ worth of data.
There are Google, Meta, and other out-of-the-ordinary datasets. But, technology has evolved, how we store and process data has changed too.
The days of needing to write some PySpark every time you need to run a pipeline are over; that truth simply hasn’t trickled down to the masses just yet, though. There are also some hurdles left to jump over for the Single Node Rebellion that are solvable but formidable.
Back in the day.
This has remained largely unchanged from the early days to the present. Proof can be seen as far back as 2015 in this study on GitHub.

Even in the MDS age when all you hear about is data growing exponentially, most datasets that exist, let alone queries on, are not that big.
This “older” study, along with the Redshift files, proves what we all already know and is whispered under the old oak tree at midnight for fear of being tarred and feathered … whisper … most data and queries work on small datasets.
Hence, the rise of Polars, DuckDB, Daft, and the like.
Why the backlash against clusters, cost only?
Maybe, and maybe not. Times and budgets have indeed tightened up since the days of Covid, when the tech money ran hot and strong. Wasn’t anybody complaining or asking about Cluster costs back then? Today is a little different.
Cloud computing has never been cheap, at least not when you're buying from AWS.

The truth is, more memory equals more money. Remember, that doesn’t even include the cost Databricks would layer on top of your compute, for example.

You start adding that stuff together, and things get out of hand really quickly. Besides, how many Spark clusters do you know of that run a single node? Sorta defeats the purpose of distributed compute.
There is some sort of complexity that comes along with most distributed compute and clusters that come from places like Databricks. Yes, I know that has made it pretty easy, considering them against something like that God-awful EMR.
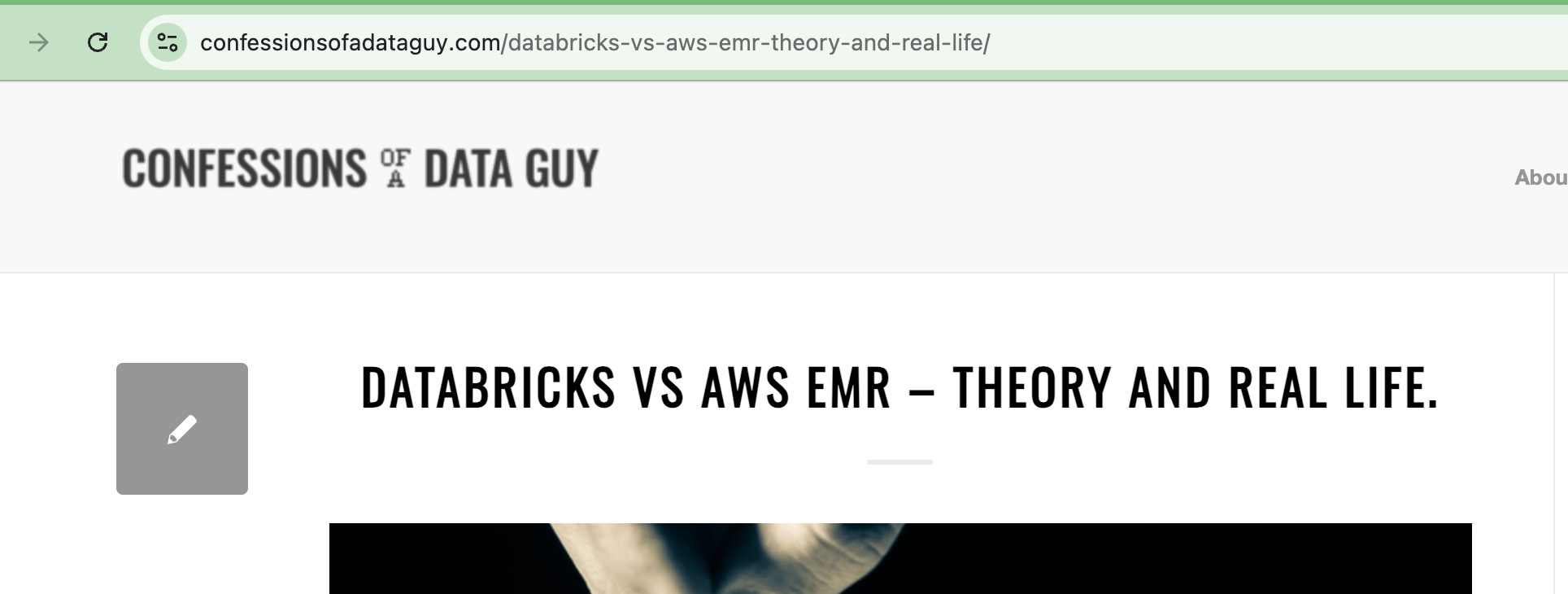
However, the rise of the Serverless approach has attempted to sidestep the complexity problem. Of course, this comes at a price, a literally big price. Like, I mean, expensive.
If you’re interested in the nuances of Serverless, in a Databricks context, when and where to use it, check out Josue Bogran on LinkedIn.

What does this all mean? Why did the “Big Saas Vendors” push so hard towards serverless, and why did the popularity of DuckDB and Polars explode so much?
Is it just a classic case of doing more with less? Complexity? A return to the draconian ways of the SQL Server past, where every GB of RAM was cared for and watched over like the Ring of Power by Golum?
There must be a business payback in some form for all this burned computing cost. New products, better insights, the ability to be more “data driven,” something.
Enter the world of “fast” and “streaming” computation.
My guess is that it was the perfect storm of data and global economics coming together at the right time. The renewed focus on actual compute and SaaS vendor spend, the need to reduce costs, and save money. The “discovery” of fast (Rust and C-based) underpinnings that can drive (Python) top-level frameworks. Continued ability to reduce memory usage by streaming computations on OOM datasets.
Costs storm-crows coming home to roost.
Advanced low-level-ish fast-ish frameworks wrapped in Python
Working on larger-than-memory datasets is becoming mainstream.
Being reminded that your data isn’t that big.
To prove your fealty to the Single Node Rebellion, you can now visit my new Merch page for this Substack and purchase the shirt. Hey, I can be a grifter too. Who do you think is paying for all my Databricks credits??!! You are.

The lazy computation that saved our weary souls from Pandas and Spark, both. Hard to understand the importance.
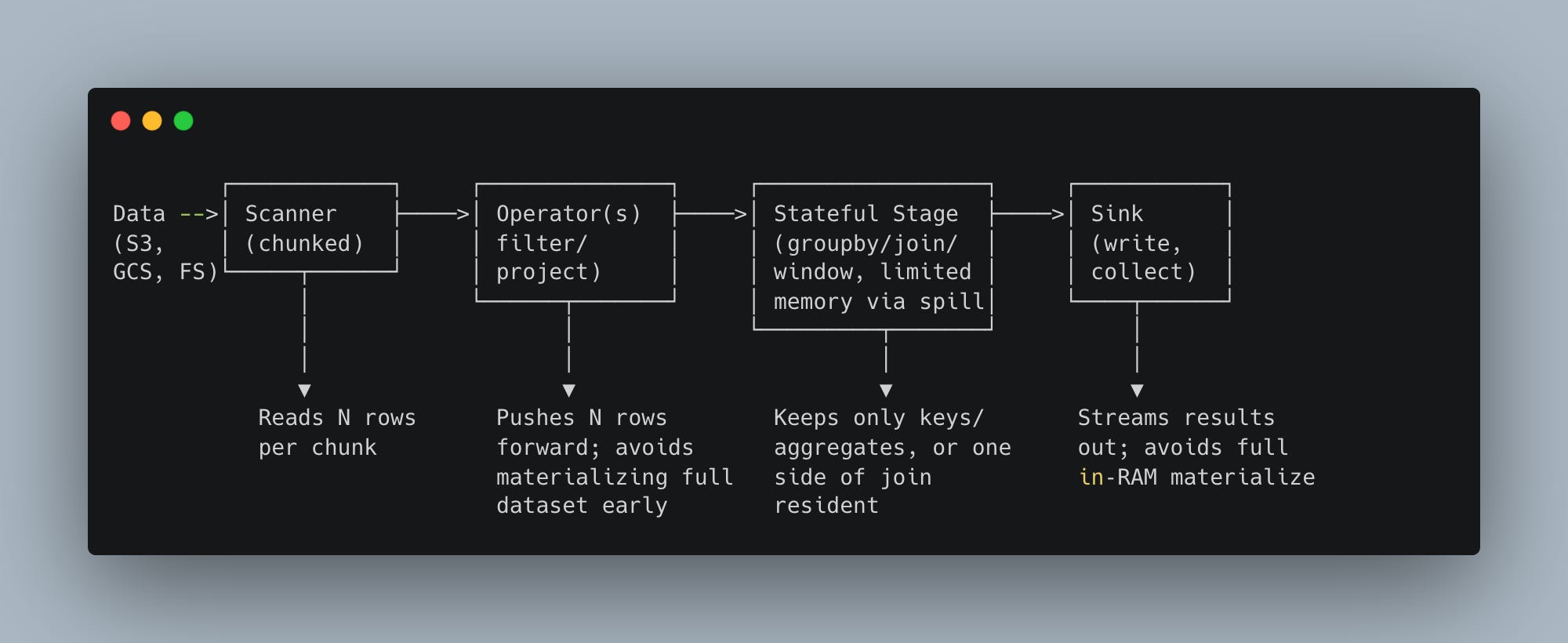
Back in the day, we either Pandas OOM it, or Spark destroyed it and us. The truth is somewhere in the middle; both sides of the Single Node Rebellion have a point.
Databricks, Snowflake, and the like offer more than just the crunch of data bewteen the teeth of bits and bytes. They offer an end-to-end Data Platform that provides EVERYTHING needed to run a Lake House at scale.
You can’t simply turn a blind eye to what these platforms have done besides charging a lot of money. They have democratized data in the whole business. AI, ML, Governance, Alerting, Data Storage, Data Compute, Dashboards, the list goes on. Compute are only how they make money, not how they get their hooks in you.
Let’s prove a point.
The point is not whether you can do it, that is, join the Single Node Rebellion, but do you have the guts to do it in production on your data stack? It’s easy.
Let’s prove the point by using an 8GB Linode instance …
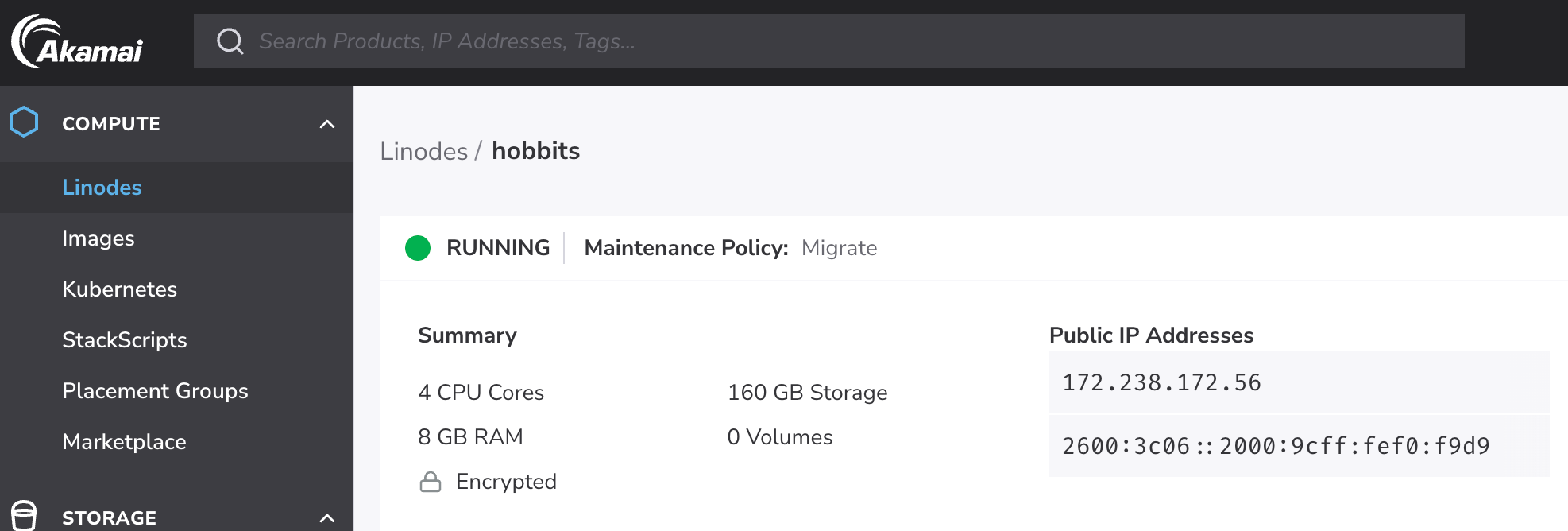
To process 50GB of CSV data.
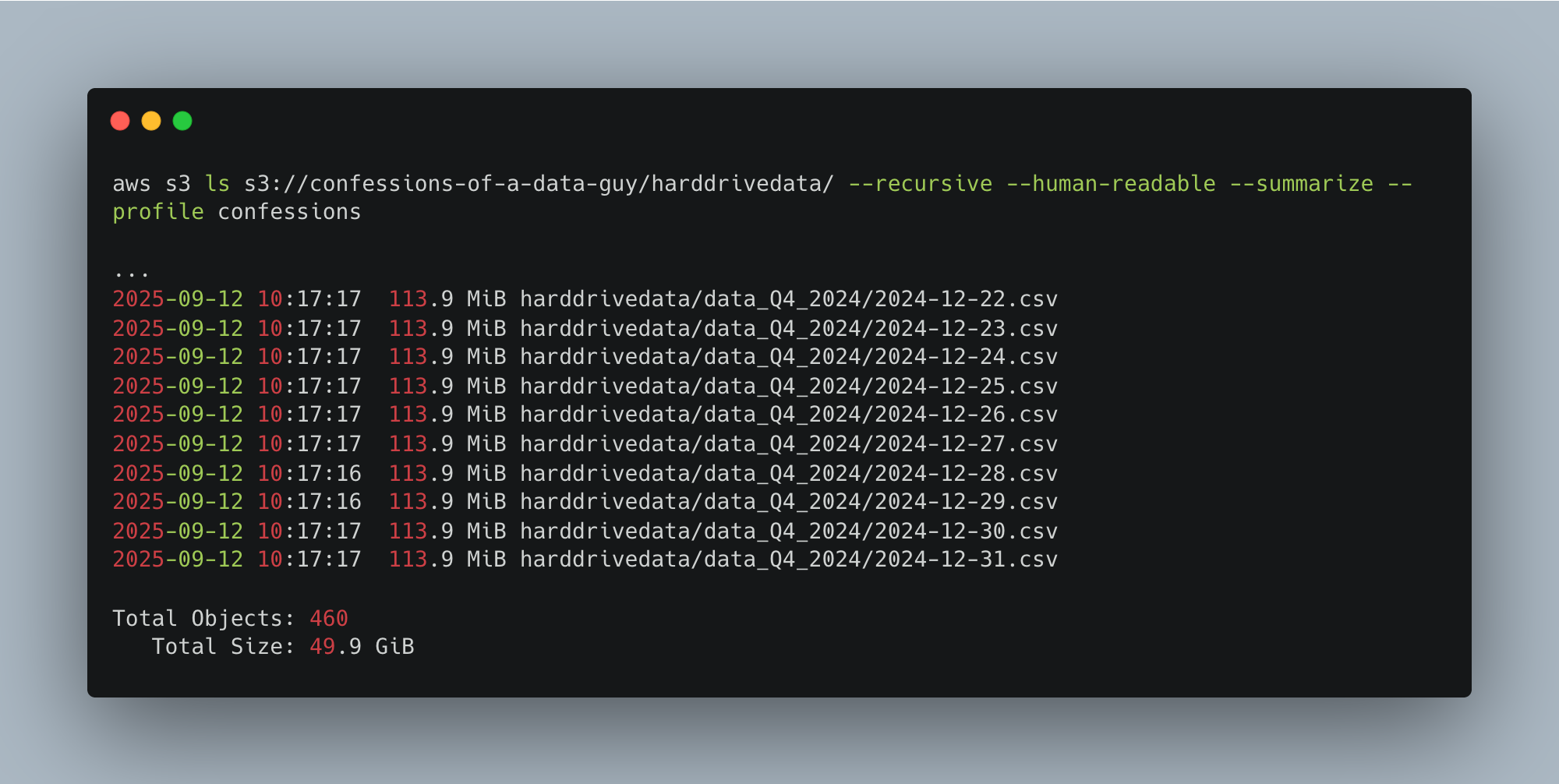
In the bygone years, Pandas would have puked on something like this, and everyone reached for Spark or something else.
We can reach for Polars …
We old dogs need to learn new tricks. Instead of reaching for a heavy hand with a Spark Cluster, we need to turn to commodity hardware on Linux with limited memory.
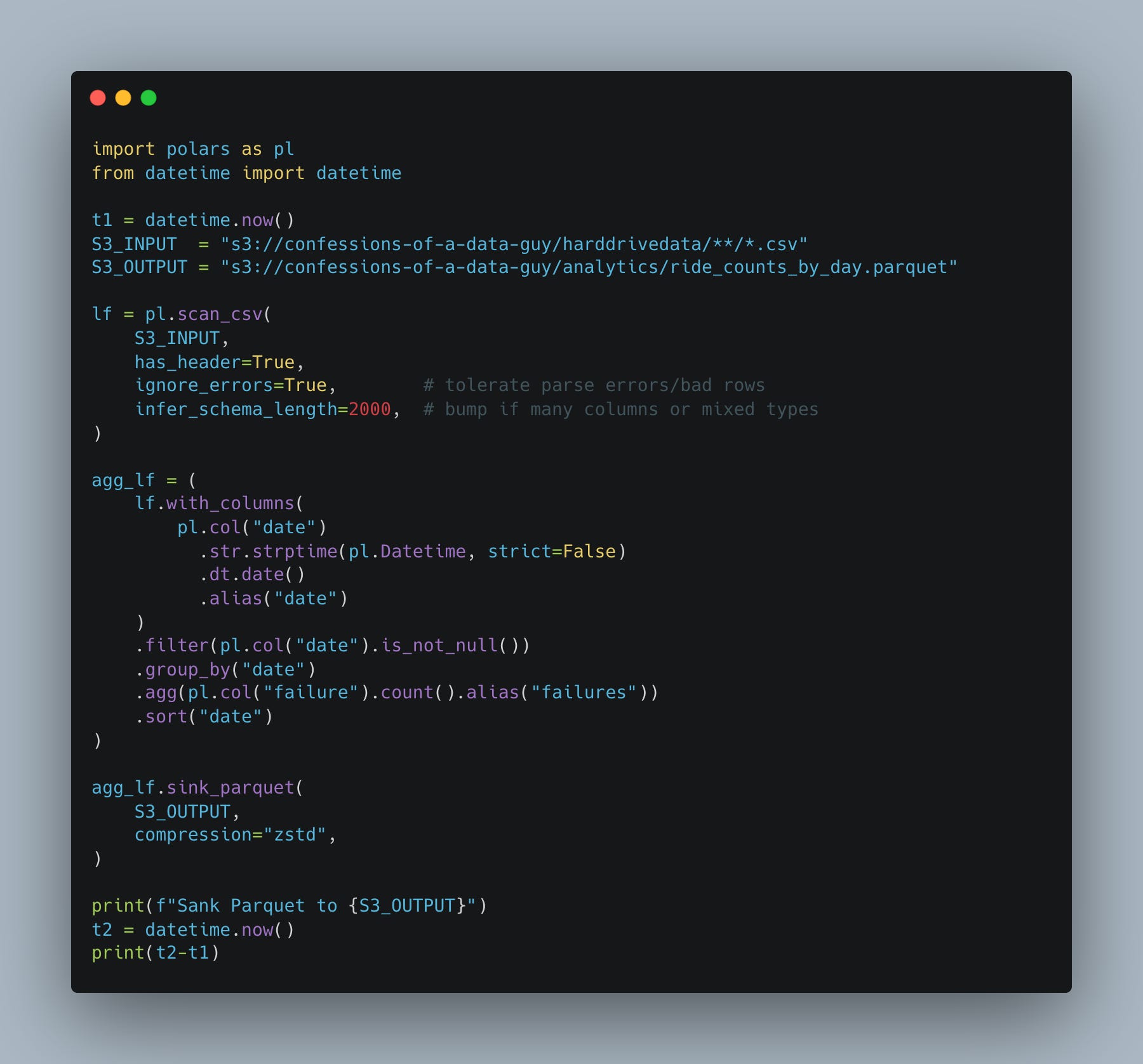
I mean, it takes less than 2 minutes to do such work.
root@localhost:~# python3 hello.py
/root/hello.py:28: UserWarning: ‘(default_)region’ not set; polars will try to get it from bucket
Set the region manually to silence this warning.
agg_lf.sink_parquet(
Sank Parquet to s3://confessions-of-a-data-guy/analytics/ride_counts_by_day.parquet
0:01:58.106536The code is concise, the cost is minimal, and the runtimes are brief. Why aren’t more people doing this sort of thing? I do not know. In the past, it was more about infrastructure, but now that Polars Cloud is here …
You can use tools like Polars and DuckDB to handle Iceberg and Delta Lake, so the Lake House is also an option.
I do think that one of the biggest “blockers” that keeps people from simply replacing a particular Databricks, Snowflake, or whatever pipeline with Polars or DuckDB … is infrastructure.
WHERE are we going to run this compute? This isn’t that easy.
If you think about it, this is what the Databricks and Snowflake SaaS vendors provided, and this is why they are popular. It’s not just Spark and compute, it’s the ease of writing code and running the compute on the same platform without thinking about it.
It’s taken the DuckDBs and Polars demi-gods long enough to figure out people want managed platforms and an end-to-end solution. It takes time for things to catch up.
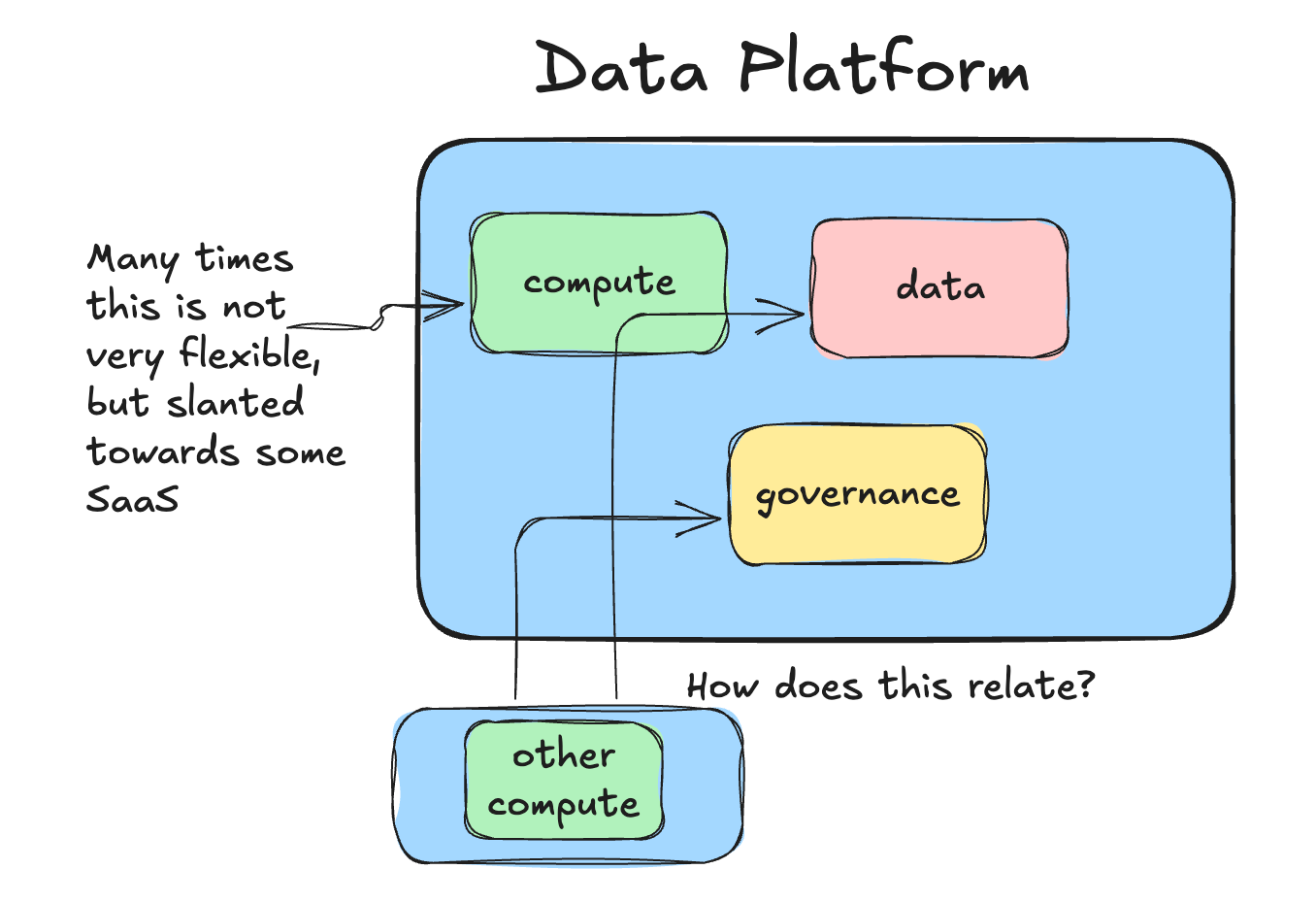
There is complexity here, like it or not. It complicates pipelines, business logic, Data Platforms, and generally everything when you start to add flexibility into systems.
Let’s say you ARE running a Databricks or Snowflake Data Platform for the majority of your workloads, but you know that at least 30% of your pipelines could easily move to DuckDB or Polars, no problem. What comes next?
code migration
integration questions as far as governance
integration into the overall platform
monitoring and alerting on new tool(s)
new testing infrastructure for new tools(s)
added complexity
That barely scratches the surface; you can’t just wave your hands in the air and say, “It will be fine.” No, it needs to work in production.
Can you simply run your new DuckDB or Polars compute on Airflow workers? Will those workloads impact other processes or cause issues? Can you get the CTO's sign-off to have a MotherDuck account?
The path to Single Node Rebellion might not be easy.
Look, the path to all rebellions that are worth anything, or going to cost you something. There is no free lunch; nothing hard comes easy.
Sure, we can reduce costs with a single-node architecture, casting off the shackles of our Clusters that have plundered our pockets for many years. However, it will require some work and mindset shifts.
Into the breach, my friends!
Great piece!
Last time I asked why we keep going full cloud / compute-heavy / Spark-based, someone told me: “because it’s cheap and it runs by itself.”
I can’t help but wonder — maybe most CTOs still prefer having a shiny “modern data platform” that seems to run effortlessly, rather than investing real time and energy in optimizing it with tools like the ones you mention.
Nice. the poll results says it all. 53% responded, I wish..