

smallpond ... distributed DuckDB?
... courtesy of deepseek-ai


When it comes to the AI hype, I pretty much have tried to ignore the constant roll of never ending models and other hoopla that is mostly meaningless. Better to let the dust settle.
Also, one of the mantras I live by is “You’re not the boss of me.” But I did have someone request I review this topic, and for once I will be nice, even though it pains me deeply.
That being said, I’ve spent plenty of time both professionally and personally fine-tuning LLMs, building RAGs, and the like. It’s lost its luster for me, no longer magic. It’s just 90% Data Engineering, prepping datasets and the like.
I’ve found that most of the time spent in working with AI is simply building datasets and a lot of DevOps-y stuff, like setting up the workflows and clusters to train etc.
This leads to today’s topic. Because “building and processing datasets” is most of the work, and based on request(s) from readers, I thought I should take a look at deepseek-ai’s new data processing tool built on/with DuckDB.
As always, what we will do isn’t rocket science, we will simply take a stick and try to poke smallpond in the eye.
smallpond - A lightweight data processing framework built on DuckDB and 3FS.

Ok, where do we start, I don’t know, let’s just get after it.
So, other than smallpond being built on top of DuckDB and 3FS, AND that it is a data processing tool, what else can we add that means anything?
“High-performance data processing powered by DuckDB”
“Scalable to handle PB-scale datasets”
It is interesting, but not surprising, off the starting line, that deepseek-ai needed to build yet another “high performance and scalable” data processing framework. Why?
People seem to be tired of Spark and want other options. We do have options now, things like Polars, Daft, etc that are built with Rust … and even DuckDB itself … but I think the key need in deepseek-ai’s case, and probably many others, is scalability.
And, scalability not in just in terms of single node fast processing, but massive datasets that are typically only tackled with Spark.
I’m going to pop some bubbles here.
Before we get into writing code and testing things, I am going to rain on a few parades here. With all the hype around deepseek-ai and now smallpond, we should toss a little cold water on ourselves to and make sure we understand what is going on.
There are going to be two users out in the world for smallpond
regular Data Engineering users on small datasets (90% of the users)
advanced users trying to use smallpond on TBs+ datasets (10% of the users)
The truth is that smallpond was made for massive scale, and there is little chance people start using it in place of duckdb or Spark for that matter.
As well, it doesn’t appear, to a layperson like me, that deepseek-ai investing some new amazing distributed thingy. They are using Ray for distributed processing.

“The High-level API currently uses Ray as the backend, supporting dynamic construction and execution of data flow graphs.” - docs
I used Ray recently to distributed some huggingface transformers LLM fine tuning, it’s a nice tool and understandable that smallpond didn’t re-invent that wheel.
I would like to start learning about smallpond (I’m under no allusions that it takes lots of time and usage to learn something well), so I will try it with two approaches.
locally with some files in s3 on a few small CSVs
just to learn the tool
try to take advantage of a Ray cluster with smallpond
just to see how hard it is and how much it breaks
One of questions I’m asking myself, and so should you, is why should I use smallpond vs little old DuckDB. The answer is probably never, but smallpond will lead to further ground breaking tools with DuckDB.
smallpond on your laptop
As always, I will throw this stuff up into GitHub for your copy and pasting pleasure. (if you haven’t started using uv, what the crap is the matter with you???)
Look ma, this is all you need to do, even your grandma could probably figure it out.
uv init try-smallpond
cd try-smallpond
uv add duckdb smallpondsmallpond seems to be very … hmmm … limited on the surface? Not much too it. But that’s a good thing. First off, the documentation sucks and is non-existent, unless you count the half-baked github stuff.
But no worries, I’m used to writing Rust, aka the code is the documentation.
import smallpond
sp = smallpond.init()Ok, well, what next?
The two main questions I have, since this is a data transformation tool, are …
what kind of data can I load, and how do I load it?
how do I apply transformations.
Neither of these questions are clearly answered in the README of the GitHub. So, basically I did a code search on smallpond for anything with “read_” to so what kind of reads they support. Based on that it appears we have two options.
(also, reading some of the code, it appears smallpond uses arrow for reads? This begs the question is smallpond using DuckDB for only in memory processing and arrow for IO?)
FYI. I could only find a single option to WRITE. write_parquet on a DataFrame is all I could see.
Look, take what I say with a grain of salt, I’m just reading the code while I sit in a school pickup carline trying to decipher what smallpond can do, since they apparently thought it was a good idea not to just tell us.
Ok, so we know how to load data, what about transform? As far as the GitHub goes the only thing it says about transform is … “Apply python functions or SQL expressions to transform data.” Although it doesn’t show you how to do said SQL, for example.
After digging though the DataFrame code some more, it looks like you can do things like filter with sql OR python expression. Aka write sql or a lambda expression, guess which one everyone will chose?
So we can …
filter
df = df.filter('a > 1')map
df = df.map('a + b as c')flatmap
df = df.flat_map('unnest(array[a, b]) as c')partial_sql (Execute a SQL query on each partition of the input DataFrames.)
c = sp.partial_sql("select * from {0} join {1} on a.id = b.id", a, b)
Again, who know’s what I’m missing, just a dude trying to figure it out. Those are all I could find. Let’s expand on our code, just try reading some s3 CSV data out of the box. I’m curious how it deals with s3 URIs.
# hello.py
import smallpond
def main():
sp = smallpond.init()
df = sp.read_csv("s3://confessions-of-a-data-guy/harddrivedata/2024-07-01.csv")
print(df)
if __name__ == "__main__":
main()uv run -- hello.pyOh lordy.
Traceback (most recent call last):
File "/Users/danielbeach/code/try-smallpond/hello.py", line 12, in <module>
main()
File "/Users/danielbeach/code/try-smallpond/hello.py", line 7, in main
df = sp.read_csv("s3://confessions-of-a-data-guy/harddrivedata/2024-07-01.csv")
TypeError: read_csv() missing 1 required positional argument: 'schema'I honestly don’t have time for that crap, no way I’m bothering writing up the schema for that CSV file. Not promising, I think I will just convert the dataset to parquet and move on with life.
Ok, we simply updated this line, and re-ran.
df = sp.read_parquet("s3://confessions-of-a-data-guy/harddrivedata/sample.parquet")Ok, that time my command line filled up with crap, but no error. So maybe let’s try a simple SQL filter and then write the results to a CSV file.
At this point I realized, duh, that smallpond is lazy and won’t trigger execution until something obvious happens, like a write.
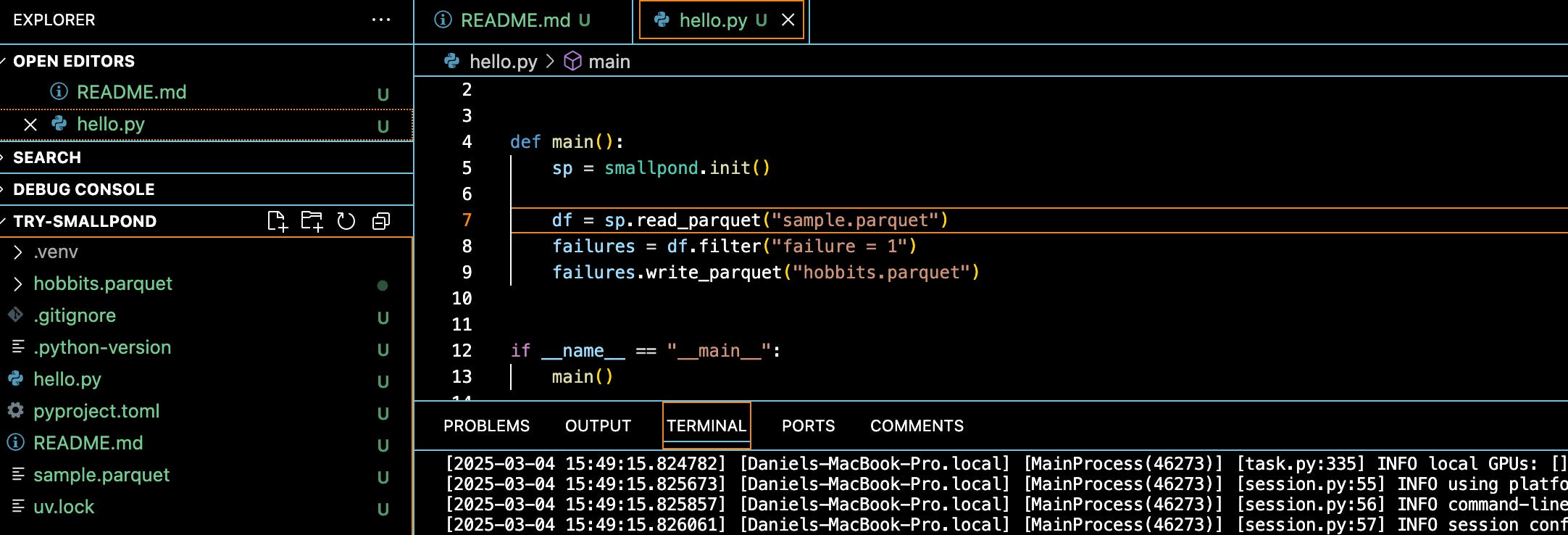
import smallpond
def main():
sp = smallpond.init()
df = sp.read_parquet("s3://confessions-of-a-data-guy/harddrivedata/sample.parquet")
failures = df.filter("failure = 1")
failures.write_parquet("hobbits.parquet")
if __name__ == "__main__":
main()Opp. That time we got an error.
File "pyarrow/error.pxi", line 91, in pyarrow.lib.check_status
raise convert_status(status)
FileNotFoundError: [Errno 2] Failed to open local file '/Users/danielbeach/code/try-smallpond/s3://confessions-of-a-data-guy/harddrivedata/sample.parquet'. Detail: [errno 2] No such file or directoryLooks like smallpond can’t interpret raw s3 URIs. I neither have the time or inclination to do any more research to use 3FS or make S3 work with smallpond somehow. Looks like we will fall back to local files.
This time with the parquet file local, it worked fine. You can see the hobbits.parquet created fine below.
Can we read the parquet file?
>>> import pandas as pd
>>> df = pd.read_parquet('hobbits.parquet')
>>> print(df)
date serial_number model capacity_bytes ... smart_254_normalized smart_254_raw smart_255_normalized smart_255_raw
0 2024-07-01 PL1331LAGXN3AH HGST HDS5C4040ALE630 4000787030016 ... NaN NaN NaN NaN
[1 rows x 197 columns]That’s a good sign, we got something to work uh.
FYI, when running smallpond code, a Ray Cluster UI is served up.
I also tried the lambda (Python) filter just to see …
failures = df.filter(lambda r: r['failure'] == 1)Worked fine.
I’m not sure I need to see anymore.
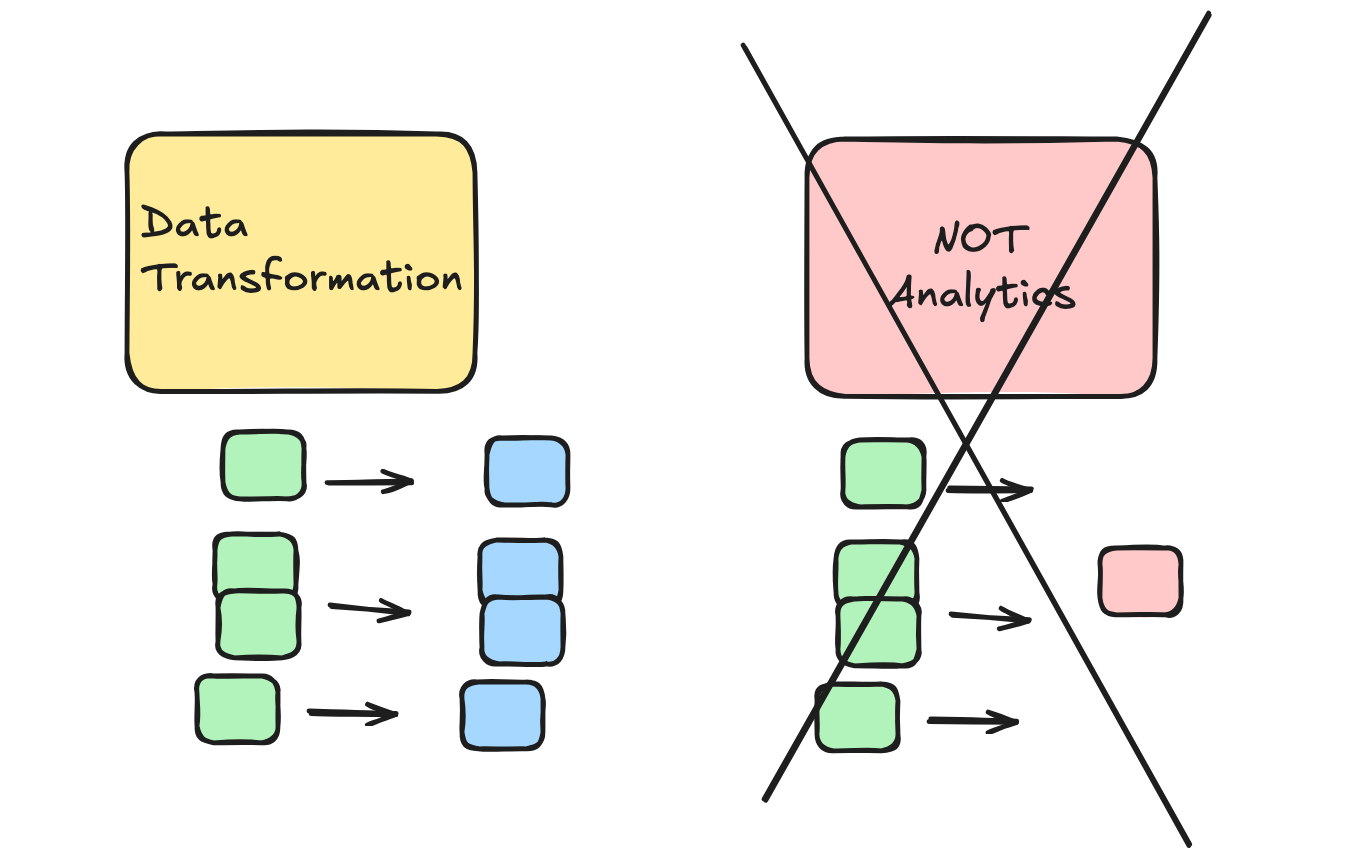
As weird as this sounds, I couldn’t figure out how I could run a simple groupBy with smallpond, strange, as it is based on DuckDB?? Maybe this old dog can’t learn new tricks, but I read through the code on the DataFrame API and could only find methods that applied to each row.
This sort of makes sense in the AI context this was created, taking in datasets, applying transformations at scale, and writing out. This is NOT an analytics tool from all appearances.
Again, be like the Bereans and figure this out for yourself, maybe I’m totally wrong.
High Level Thoughts
What do I think of smallpond? I think it’s another great addition to the Data community that continues to push forward the edges of what is possible today.
The fact that it is built on DuckDB and not the JVM is yet another win for Data Teams who are looking to escape Spark as the ONLY real option for Big Data. Those days are numbered smallpond is the proof of that, sooner or later it’s all going to change.
It seems very early stage to me, reminds of a recent incubating Apache Project we looked at. Tons of work to do in the areas of …
documentation
expanded functionality (read/write/transform)
increased usability
first class cloud integration (like s3)
If you want an even more in depth analysis of under the hood of smallpond, read this blog post.
Sounds like it’s “much ado about nothing”